更适合穷宝宝体质的英语学习办法
这套办法自己用了大半年,效果不错,分享一下。
AI都杀疯了,还有必要学英语啊?
当然的,不如说,正是因为AI杀疯了,掌握英语更重要的。
- AI 是程序员写的 ➡️ 程序员要掌握英语 ➡️ 英语还是得学
- 提问是一门学问 ➡️ 英文比中文得到的信息质量更高
- 如果你需要在中国工作生活,中文是必须的。 ➡️ 同理可得
学英语的一些过往经验总结
学英语这个需求一直存在,几乎可以说市面上的方法我都尝试过。
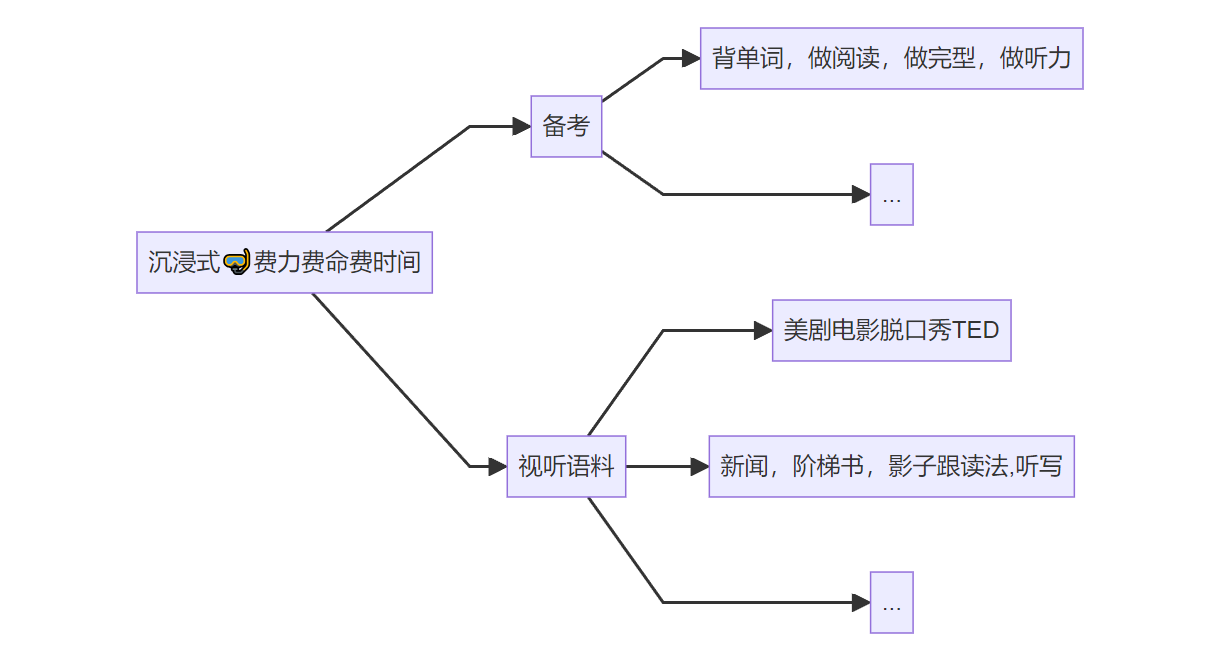
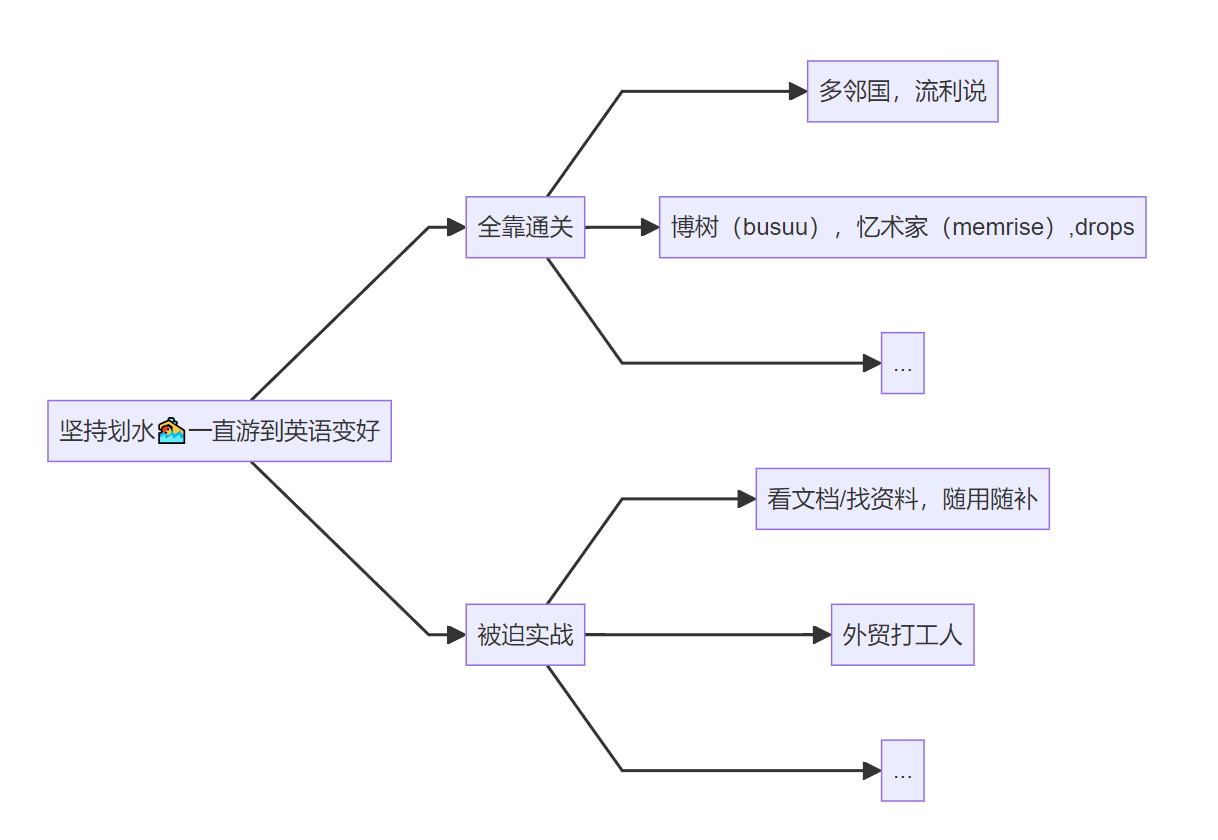
学英语的目的是什么?
这个问题非常的关键,直接关系到我的是:
- 能够旅游自助,从准备工作到实际应用。
- 掌握一种语言的逻辑来查找/筛选/处理 信息:沉浸在海量的英文信息里可以仰泳
- 比较流利的表达自己的想法,话题是比较日常和常规的,不涉及特定专业领域的术语。
现状:可以公开的情报
下面这个表,给人一种人丑怪镜子的感觉:
| 问题 | 答案 |
|---|---|
| 是否可以长时间脱产,比如沉浸式备考 | 不行,要打工 ,也不是那种有恒心毅力的人 |
| 是否可以通过 沉浸式视听语料(看美剧)学习 | 不行,全是故事情节和内容,学英语早忘了 |
| 通关的自己感觉适合吗? | 不适合,越到后面越只想打卡 |
| 被迫实战呢? | 一直被迫,一直糊弄 |
| 有预算报班嘛,都知道线下效果好 | 没钱,也没有时间去线下班 |
| 线上班呢?又便宜又方便? | 可能加班,你的便宜≠我的便宜 |
| 三个月精通英语可能吗? | 不要再做这种弯道超车的美梦了 |
梳理需求和目标的关系
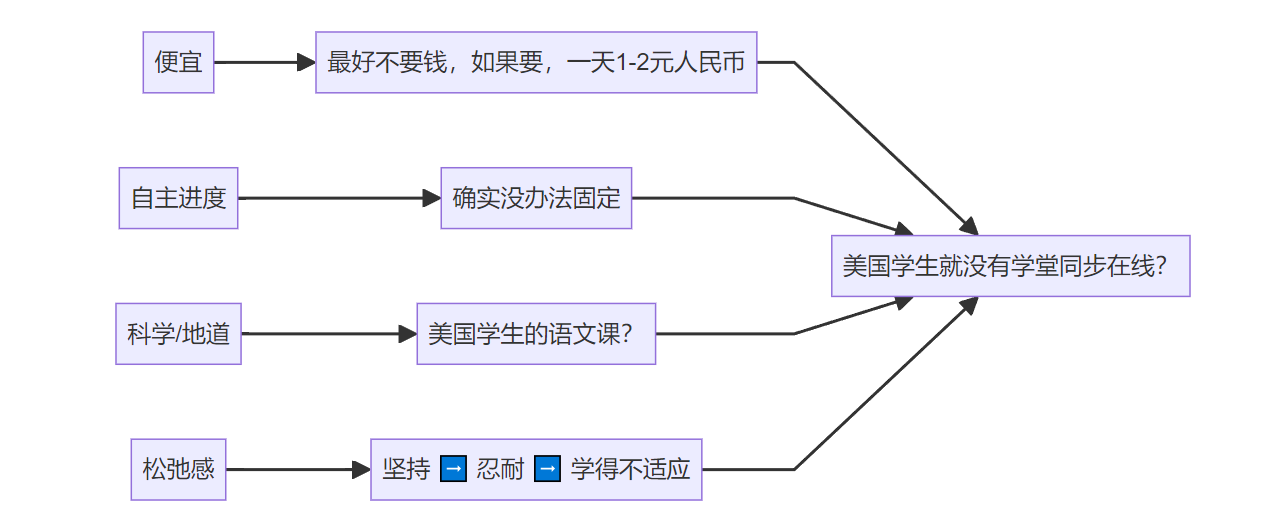
一站式方案
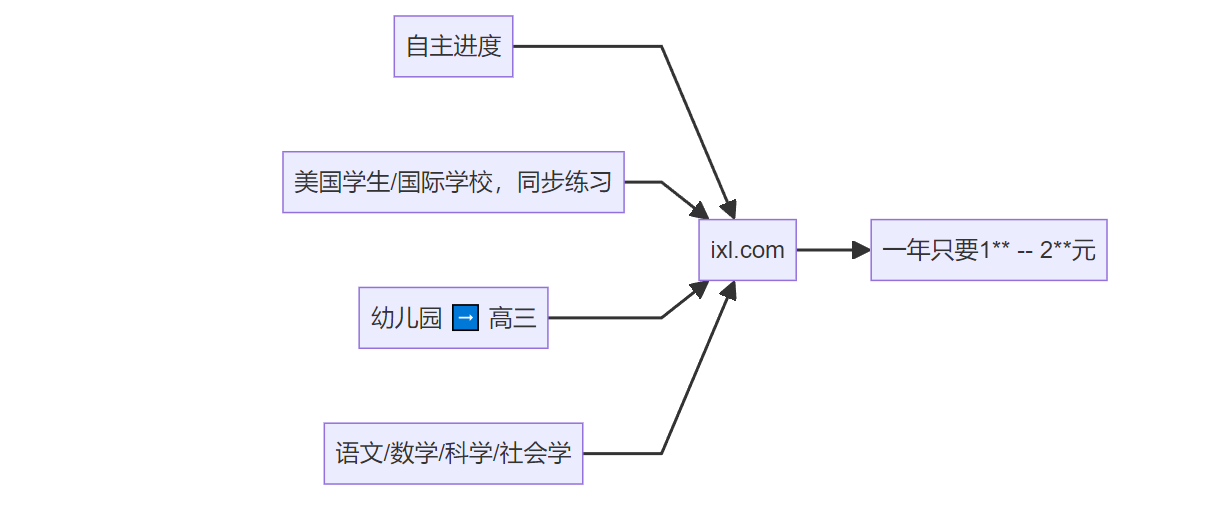
一年200来块就解决了......
K12 结构
3个月学会英语 听起来很扯,永远有人做到,但就是不是我。但是老外的语文同步测验你每本都刷了,每次都通过了考试,你说你英语差,这咋可能。
学习语言讲究输入量,而根据多语言学家的说法,母语水平至少需要百万级别的阅读量,也就是说,对于天分/效率差一些的/过了语言习得期的,百万级别也不一定就能到达母语水平。
多学科 + 便宜
| 学科名字 | 对应的中文学科 | 学习建议 |
|---|---|---|
| language arts | 语文课 | 必学 |
| social studies | 思想品德/历史人文/社交礼仪 这些课程 | 必学 |
| science | 自然/地理/天文/物理 | 看个人爱好学 |
| math | 数学课 | 我感觉中国人没啥必要 |
¥1元/天 不到,四个学科学一年,让人震惊。
自主进度
全程自学,题目多到头大,下面是大致的进度效果推测(以作者本身经验为参照,并不准确),从一年级开始:
| 每天花费时间 | 周期 | 效果 |
|---|---|---|
| 30分钟 | 6个月 | 可以学完一个年级的language arts |
| 2h | 3个 | 可以学完一个年级的language arts + social studies |
怎么买?
其实它这个家庭套餐挺贵的;班级套餐,一般人又凑不上那么多号一起均摊。
还有地区版本问题,英美澳地方不同价格也会不同,但是对我们老中都没区别,都是英语。
淘宝/咸鱼 搜一下有些卖家有渠道分销,其实就是班级套餐。
关键词:IXL单独官网账号 独立记录 全科解锁 数学英语社会科学 可用APP (其实ixl还支持学习西班牙语)
背景
需要验证一下A卡炼丹,然后发现真是小众的需求呢,非常的有得折腾,因此写了这篇笔记。算了一下,一共耗时5-6个小时。
已经知道的情报
设备情况
AMD RT 5700XT
Windows 10
方案一 适用于AMD6600以上
记录一下过程
参考教程
- AMD如何使用ComfyUI, 这个作者的显卡是6600XT
- AMD GPU + Windows + ComfyUI! How to get comfyUI running on windows with an AMD GPU! 这个作者是上面作者参考的作者。
安装anaconda
下载地址:anaconda
最后的时候最后记得勾选 add to PATH.
运行anaconda
菜单栏 anaconda prompt ,等于是配套的命令行工具。
创建环境
conda create --name comfyui python=3.10.12
使用 Conda 工具创建了一个名为 "comfyui" 的虚拟环境,并指定了 Python 版本为 3.10.12。
这个环境对应在本地的d:\libregd\anaconda\envs\comfyui ,文件夹生成在哪里,取决于安装anaconda的时候你选了安装在哪个盘哪个文件夹,默认是C盘。
激活虚拟环境
conda activate comfyui
conda activate: 这是 Conda 包管理工具的一个命令,用于激活虚拟环境。comfyui: 这是你想要激活的虚拟环境的名称,在这个例子中就是 "comfyui"。执行这个命令后,你的命令行提示符将会更改,显示当前已激活的环境名称,这意味着你正在使用指定的虚拟环境。这样,你就可以在这个环境中安全地运行 Python 脚本或者安装其他依赖,而不会影响到系统中的其他环境。
这使得用户可以在不同的环境中工作,每个环境可以有自己独立的软件包集合和配置。
拉取comfyUI并进入
git clone https://github.com/comfyanonymous/ComfyUI.git
cd comfyui
进入环境以后,主要是先下载comfyUI,然后进入对应的目录。
安装torch和别的配置
pip install torch-directml
https://pypi.org/project/torch-directml/
这个是torch的特别版本,可以说是为了AMD专门搞出来的。
Successfully installed MarkupSafe-2.1.5 filelock-3.14.0 fsspec-2024.5.0 jinja2-3.1.4 mpmath-1.3.0 networkx-3.3 numpy-1.26.4 pillow-10.3.0 sympy-1.12 torch-2.2.1 torch-directml-0.2.1.dev240521 torchvision-0.17.1 typing-extensions-4.12.0
可以看得出来安装的东西比较多。 torch-2.2.1
pip install -r requirements.txt
Successfully installed aiohttp-3.9.5 aiosignal-1.3.1 async-timeout-4.0.3 attrs-23.2.0 certifi-2024.2.2 charset-normalizer-3.3.2 colorama-0.4.6 einops-0.8.0 frozenlist-1.4.1 huggingface-hub-0.23.1 idna-3.7 kornia-0.7.2 kornia-rs-0.1.3 multidict-6.0.5 packaging-24.0 psutil-5.9.8 pyyaml-6.0.1 regex-2024.5.15 requests-2.32.2 safetensors-0.4.3 scipy-1.13.1 tokenizers-0.19.1 torchsde-0.2.6 tqdm-4.66.4 trampoline-0.1.2 transformers-4.41.1 urllib3-2.2.1 yarl-1.9.4
这条也有好多安装的。
启动comfy
python main.py --directml
Using directml with device: Total VRAM 1024 MB, total RAM 32701 MB pytorch version: 2.2.1+cpu Set vram state to: NORMAL_VRAM Device: privateuseone VAE dtype: torch.float32 Using sub quadratic optimization for cross attention, if you have memory or speed issues try using: --use-split-cross-attention ****** User settings have been changed to be stored on the server instead of browser storage. ****** ****** For multi-user setups add the --multi-user CLI argument to enable multiple user profiles. ******
Import times for custom nodes: 0.0 seconds: C:\Users\libregd\ComfyUI\custom_nodes\websocket_image_save.py
Starting server
To see the GUI go to: http://127.0.0.1:8188
pytorch version: 2.2.1+cpu 这句话说明还是用的cpu啊
这样启动成功的comfyUI有啥意义?自闭了,关掉命令行。
不过如果正常,没有这句话,也就是AMD显卡信号6600+可以考虑继续跟着方案一的参考教程做完后续。
验证猜想
DirectML是啥?
chatGPT:
使用 DirectML 支持的 PyTorch 版本来利用 AMD GPU 时,对 GPU 型号有一些要求,但你的 AMD RX 5700 XT 是支持的。DirectML 是一个跨平台的机器学习加速库,旨在为 Windows 10 上的各种 GPU 提供支持,包括 AMD 和 NVIDIA 的显卡。
DirectML 可以在支持 DirectX 12 的 GPU 上运行。AMD RX 5700 XT 支持 DirectX 12,因此可以使用 DirectML。
在pip install torch-directml以后,就已经安装了特定的torch,就可以用下面的代码验证你的 AMD GPU 是否可以使用 DirectML:
# testTorchVer.py
import torch
# 检查 DirectML 设备是否可用
if torch.cuda.is_available():
device = torch.device('dml')
print("DirectML device is available.")
else:
device = torch.device('cpu')
print("Using CPU as fallback.")
# 创建张量并移动到 DirectML 设备
tensor = torch.tensor([1.0, 2.0, 3.0]).to(device)
# 打印张量信息
print(tensor)
print(f"Tensor device: {tensor.device}")
怎么放到对应的虚拟环境下?
毕竟实在虚拟环境下进行的以上各种安装配置,因此我感觉测试也得放到这个环境中。
(base) C:\Users\libregd>cd ComfyUI
(base) C:\Users\libregd\ComfyUI> conda activate comfyui
上面这两个命令,通过菜单栏的anaconda prompt进入对应的文件夹(不确认是否必须),并激活虚拟空间,然后就会变成这样:
(comfyui) C:\Users\libregd \ComfyUI>
查看torch版本
pip show torch
Name: torch Version: 2.2.1 Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration Home-page: https://pytorch.org/ Author: PyTorch Team Author-email: packages@pytorch.org License: BSD-3 Location: d:\libregd\anaconda\envs\comfyui\lib\site-packages Requires: filelock, fsspec, jinja2, networkx, sympy, typing-extensions Required-by: torch-directml, torchvision
看得出来torch版本是非常新的。
echo不好用
尝试了echo ,python test.py可以运行,但是毕竟这个文件还是文本比较多,不太适合。
(comfyui) C:\Users\libregd\ComfyUI>echo print("hello!!!!!!") > test.py
navigator也不支持
Anaconda Navigator 是anaconda配套的GUI,可以管理不少事:
chatGPT:
在 Anaconda Prompt 中创建的环境可以在 Anaconda Navigator 中访问。Anaconda Navigator 是一个用于管理 Conda 环境和软件包的图形用户界面(GUI)工具,它可以显示并管理所有通过 Conda 创建的环境,无论是通过命令行还是通过 Navigator 自身。
当你在 Anaconda Prompt 中创建一个新的环境后,它会自动显示在 Anaconda Navigator 的环境列表中。你可以在 Navigator 中切换到这个新创建的环境,并在其中安装、更新或删除软件包,就像在命令行中一样。这使得在 GUI 和命令行之间切换变得更加方便,以满足用户不同的需求。
- 在 Navigator 中的 "Home" 标签下,点击 "Environments"。
- 在 "Environments" 页面中,选择你想要安装 Notepad++ 的环境(比如 base 或者你自己创建的环境)。
- 在环境列表中,选择 "Not installed",然后在搜索框中输入 "notepad++"。
- 在搜索结果中找到 Notepad++,勾选它,并点击 "Apply" 按钮来安装。
- 安装完成后,你就可以在 Anaconda Prompt 中使用 Notepad++ 了。
实际并不行,里面压根没有notepad++,也没有vim/vi ,也没有vscode,天。
jupyter notebook 正解
anaconda是一组套件,还有个jupyter notebook,总之在程序启动栏点开就打开了一个web浏览器:
http://localhost:8888/tree
我:是否可以通过访问jupyter notebook访问anaconda的虚拟环境下的各种文本文档,比如.txt .py .js ?以及新建各种文本文档。
chatGPT:
Jupyter Notebook 可以访问 Anaconda 虚拟环境下的各种文本文档,包括 .txt、.py、.js 等文件。当你在 Jupyter Notebook 中打开一个 notebook 文件时,你可以通过文件系统浏览器或者 Jupyter Notebook 提供的命令来访问并操作虚拟环境下的其他文件。
具体来说,你可以在 Jupyter Notebook 中使用以下方式来访问虚拟环境下的文件:
- 通过文件系统浏览器: Jupyter Notebook 提供了一个文件系统浏览器界面,你可以通过界面上的文件夹图标来浏览虚拟环境下的文件和文件夹。你可以单击文件夹图标进入文件夹,查看其中的文件;也可以单击文件图标打开文件进行编辑。
- 通过命令行: 在 Jupyter Notebook 的代码单元格中,你可以使用系统命令来访问虚拟环境下的文件。比如,你可以使用 Python 的内置
open()函数来读取和写入 .txt 和 .py 文件;或者使用其他命令来执行一些操作,比如在虚拟环境中创建新的文件。- 通过 Jupyter Notebook 的扩展功能: Jupyter Notebook 还支持各种扩展功能和插件,你可以安装一些扩展来增强 Jupyter Notebook 的文件操作能力。比如,安装 JupyterLab 可以提供更强大的文件管理和编辑功能,包括新建文件、复制粘贴等操作。
总之,通过 Jupyter Notebook 可以方便地访问和操作 Anaconda 虚拟环境下的各种文本文档,并且可以通过安装扩展来增强文件操作的功能。
总之通过在http://localhost:8888/tree/ComfyUI 这个浏览器页面中,实现了新建文件,编写文件testTorchVer.py。
本地文件夹 正解
C:\Users\libregd\ComfyUI
在这个地方我找到了新建的testTorchVer.py,也就是说,anaconda确实虚拟了一个环境。只在自己的生态内(anaconda prompt,anaconda navigator,Jupiter notebook)映射你创建的内容。
验证结果
总算可以验证了,
(comfyui) C:\Users\libregd \ComfyUI>python testTorchVer.py
Using CPU as fallback. tensor([1., 2., 3.]) Tensor device: cpu
也就是说,特定的torch-directml并没有真的支持AMD 5700,至少comfyUI隐晦的暗示了AMD的显卡型号底线。
https://github.com/comfyanonymous/ComfyUI?tab=readme-ov-file#running
For 6700, 6600 and maybe other RDNA2 or older:
HSA_OVERRIDE_GFX_VERSION=10.3.0 python main.pyFor AMD 7600 and maybe other RDNA3 cards:
HSA_OVERRIDE_GFX_VERSION=11.0.0 python main.py感觉5700版本太低了哈哈哈。
删除虚拟环境
conda remove --name comfyui --all
这个不是我很想要的效果,所以我删除了这个虚拟环境。d:\libregd\anaconda\envs\comfyui 确实随着这条命令消失了。
然而C:\Users\libregd\ComfyUI 这个拉取的github仓库还存在。
方案二 windows下webUI天选分支
A卡买的时候,价格真香了。5700 XT 可以双系统 win + mac 赚到了。炼丹的时候,低端A卡落泪了 (A卡生态不挤牙膏,我推测导致核心在版本号之间变动特别大,directML估计感觉钱少事多收益不行,就没兼顾太多A卡。)
AMD 5700XT 即便是在Linux下都需要很多额外的设置,比如
pip install torch==1.13.1+rocm5.2 torchvision==0.14.1+rocm5.2 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/rocm5.2
rocm 专供linux用,虚拟机/wsl 可能都不好使,双系统/云主机应该可行(也就是要操作系统就是linux),但是我没有计划把win换成linux,双系统也不是个策略,因为日常软件生态暂时在win。
参考资料
- How to ComfyUI on AMD Radeon RX 5700 XT :这篇提供了一个相对详细的安装过程命令详解, but linux
- HIP error: invalid device function when running ComfyUI : 这篇很多关于directML的缺陷讨论。
结论
假设不搞comfyUI,退一步海阔天空,找stable-diffusion-webui:Install-and-Run-on-AMD-GPUs, 就会发现,
这个分支维护者自己好像就是5700 :I can't reproduce it with my RX 5700 XT , 不过看修bug ,完全是自己的需求,结果issue里充满了各种他没办法干涉的疑难杂症,看着就心累。
但是我已经不想玩webUI了,即便我没怎么玩,我想玩节点的comfyUI.
方案三 云端部署comfyUI
有些钱还是要花的
-
Your Options for Running ComfyUI in the Cloud :分析了怎么在云上搞得几种策略和推荐了一些产品,等于导读。
-
云端安装 ComfyUI:给出了非常详细的教程,和省钱指南,方案三的主要参考教程。
步骤要点
- 推荐了kaggle,主要是每个星期可以白嫖GPU(T4 × 2) 30个小时,以代码启动后的时间点开始算。也就是说暂停服务就可以完全够用了,不用像国内一样,管你用不用都在计费。
- kaggle需要手机验证,老中号码可行。我感觉换个邮箱+接码平台可以无限白嫖。(但30h对我来说一周完全足够了)
本文总结
折腾半天还是上云了,现在的要点是学习comfyUI,这个界面乍看很眼熟,毕竟blender里也有几何节点.
以及我第一次用comfyUI,就是仅仅使用cpu性能在blender里使用的插件:ComfyUI-BlenderAI-node
后续的安排是总结学习comfyUI的经验,这篇文章起因是想验证一个画画前期的测试想法,现在感觉像个踩坑吐槽文。
背景
《创字录》 这本书买蛮久了,一直没看,现在感觉需要提升字体的设计水平。
计划是尽量用上自己已经有的思维来解构/扩展书籍,而非单纯的跟练。
视频教程
也会搭配一些案例和illustrator的实战来练习,同时提升对illustrator的掌握。
文字基础
讲文字从视觉结构上的构成,汉字,拉丁都涉及了。
汉字空间结构
这部分讲了几种基本的结构,以及举例的汉字。我将其作为素材制作为A4尺寸的文件打印出来,方便自己描摹轮廓,从而更深的体会不同之处。主要采用了4种在印刷中用得最多的字体:楷体,宋体,仿宋,黑体。

备注:
- 还是个数安排多了,一张A4放1-4个字就够了,不然描勾边的时候真的费眼睛。
- 这个分类法是从字体设计的角度分的,还可以从汉字规范的角度分:汉语字典-结构分类
主要就是不想学了暂时。
背景
网课地址:UBCx: How to Code: Simple Data, 不要钱的。
- 周期大概是7week,自主进度。
- 我会采用和大纲相匹配的方式,梳理,总结,包含课程练习。
1a: Beginning Student Language
这一部分内容也不少,但从标题来看比较简单入门。
Expressions
课程鼓励通过自己动手来学习,并且撂狠话:如果只听课和看答案,几乎一定会失败。(这个几乎就很内涵)
课程要求安装软件:the latest version of Dr Racket.
Q:你知道 DrRacket 这个软件吗?
chatGPT:
DrRacket 是一个广泛用于教学和研究的编程环境,特别适用于 Racket 编程语言。Racket 是一种多范式编程语言,源自 Lisp 家族,具有强大的宏系统和模块系统,适合各种编程任务。
DrRacket 的特点包括:
- 集成开发环境 (IDE):提供了编写、运行和调试 Racket 程序的综合环境。
- 交互式界面:允许用户在交互式窗口中输入和执行代码,方便测试和学习。
- 错误报告:详细的错误报告和诊断工具,帮助用户快速找到和修复问题。
- 教学功能:内置了许多教学工具,适用于计算机科学入门课程,如程序设计基础 (How to Design Programs, HtDP) 课程。
- 多语言支持:不仅支持 Racket,还支持多种其他编程语言,使其成为多语言开发的有力工具。
DrRacket 广泛用于教育领域,因为它能帮助学生逐步理解编程概念和技巧,同时提供一个易于使用的界面,促进动手实践和实验。
Q: 使用 DrRacket 进行一般的数学性运算,请给出例子和示范。(省略了最基础的+-*/ )
chatGPT:
; 多项加法 (+ 1 2 3 4) ; 结果是 10 ; 嵌套运算: (+ (* 2 3) (/ 10 2)) ; 结果是 11 ;负数运算: (- -5 3) ; 结果是 -8 混合运算: (/ (+ 4 -12 6.2) 3) ; 结果是 -0.6 ; 求幂 (expt 2 3) ; 结果是 8 ; 平方根: (sqrt 16) ; 结果是 4 ; 对数 (log 10) ; 结果是自然对数 ln(10) ; 三角函数: (sin (/ pi 2))
;等于一般编程语言中的注释。
总结
这堂课最重要的是引入了:operator , value, expression ,这三个概念。
在(* 5 6)中,5和6是value, * 是operator,( ) 这个整体则是expression.
几乎所有的编程语言,最基本的单元都由这三个结构组成。
作业
When we want to compute the average of 4, 6.2 and -12, all three of the following expressions evaluate to the correct result. Which expression do you think is the best, and why?
A. (/ (+ 4 6.2 -12) 3)
B. (/ (+ -8 6.2) 3)
C. -0.6
D. Doesn't matter, all are equally good.
My Answer: A
My explanation: "The second answer is partly using the human brain to calculate 4 plus -12, and the third answer is to calculate entirely with the human brain. Programming means letting the computer do it as much as possible."
Evaluation
;从上到下,一步一步的运算过程
(+ 2 (* 3 4) (- (+ 1 2) 3))
(+ 2 12 (- (+ 1 2) 3))
(+ 2 12 (- 3 3))
(+ 2 12 0)
14
(+ 2 (* 3 4) (- (+ 1 2) 3)) ,ok,这么一大坨 primitive 被call
直观上就两点:从左到右,从内到外。
计算机是这么理解的:
step 1:我想运行 (+ 2 __ __) 发现第二个本来想要value,没直接给,给了 (* 3 4) 这么个primitive,于是进去看看,发现能call ,因为(* 3 4) ,是 (operator value value) ,能干。 于是我就干了这一件事。
step2: (+ 2 12 __) 然后这个也不符合全value,第三位也是个primitive(- (+ 1 2) 3),我进去一看,里面还有个primitive(+ 1 2),于是也只干了一件事,得到(+ 2 12 (- 3 3))
step3: 同理,得到(+ 2 12 0)
step4 : 总算能进行call了 ,(operator value value value) call out 14
Q:课程采用了BSL language,为什么不用Racket?
chatGPT:
当使用BSL语言和Racket语言时,以下是一个简单的例子来展示它们之间的区别:
1. 使用BSL语言的例子:
假设我们要编写一个程序来计算两个数的平方和。在BSL语言中,代码可能如下所示:
(define (square-sum a b) (+ (* a a) (* b b))) (square-sum 3 4)在这个例子中:
define用于定义一个函数square-sum,该函数接受两个参数a和b,并返回它们的平方和。(* a a)计算a的平方,(* b b)计算b的平方。(+ (* a a) (* b b))将两个平方数相加。square-sum 3 4调用定义的函数,并输出结果。这种简单的语法和功能限制有助于初学者理解函数定义和基本算术运算。
2. 使用Racket语言的例子:
现在看看同样的例子,但是使用Racket语言:
(define (square-sum a b) (+ (square a) (square b))) (define (square x) (* x x)) (square-sum 3 4)在Racket中:
square函数被定义为计算一个数的平方。square-sum函数使用了square函数来计算a和b的平方和。square-sum 3 4同样调用函数并输出结果。相比BSL,Racket的语法更接近传统的Lisp风格,更加灵活和表达力强。函数可以更复杂,语言本身支持更多的编程范式和高级功能,如闭包、宏等。
区别总结:
- 语法和功能限制:BSL有明显的语法和功能限制,使其更易于初学者理解和使用。
- 表达能力和灵活性:Racket提供了更广泛的语法和功能,适合开发复杂的程序和进行更深入的编程探索。
这些例子展示了在教学和实际编程中使用BSL和Racket时的主要区别,选择哪种取决于学习者的背景和学习目标。
总结: the first evaluation rule, the primitive call rule.
strings and images
strings
要点:calls to string and image primitives work just like calls to number primitives。(规则和之前的一样)
"Ada"
;"Ada"
(string-append "Ada" "Love" "coding")
;"AdaLovecoding"
(string-append "Ada " "Love " "coding.")
;"Ada Love coding."
(string-append "Ada" " " "Love" " " "coding")
;"Ada Love coding"
;(string-append 1 "11")
;string-append: expects a string, given 1
;(+ "123" "123")
;+: expects a number, given "123"
;(string-add "1" "11")
;string-add: this function is not defined
(substring "halo world" 0 3)
;"hal"
(substring "halo world" 3 6)
;"o w"
总结: 主要强调了index下标的问题,从0开始,以及左开右闭。
images
要点:很像小海龟..... 或者 svg.
- 我注意到他称呼 above/beside/overlay 为primitive ,
(require 2htdp/image)
(circle 10 "solid" "gray")
(circle 20 "solid" "gray")
(circle 30 "solid" "gray")
(rectangle 30 60 "outline" "skyblue")
(text "hello" 24 "orange")
(overlay (circle 10 "solid" "red")
(circle 20 "solid" "yellow")
(circle 30 "solid" "blue"))
我:解释上面代码的第一句
chatGPT:
在Racket或BSL中,当你看到类似
(require 2htdp/image)这样的语句时,它是在引入或导入一个模块或库。让我们逐步解释这句话:
(require 2htdp/image):
require是一个特殊的语法,用于加载或引入其他模块或库,使得其中定义的函数、变量和数据类型可以在当前代码中使用。2htdp/image是一个特定的模块名称。在Racket的教学环境(如BSL或DrRacket中),这个模块提供了处理图像和绘制图形的功能。
- 功能:
- 引入
2htdp/image模块后,你可以使用该模块提供的函数和数据类型来创建和操作图像。例如,你可以绘制各种形状(如圆形、矩形)、编辑图像,以及在图像上进行文本标注等操作。
- 示例:
- 在你的示例中,
(circle 10 "solid" "gray")是在使用引入的2htdp/image模块中的函数circle来绘制一个半径为10的实心灰色圆。
我:如果我想绘制一个十字架,如何做?
chatGPT:
(require 2htdp/image) (define (cross-star size) (overlay (rectangle size 10 "solid" "black") (rectangle 10 size "solid" "black"))) ; 绘制一个大小为 100 的十字架 (cross-star 100)
我:可以指定一个圆出现在一个固定的坐标吗?
chatGPT:
(require 2htdp/image) (place-image (circle 50 "solid" "red") 100 100 (rectangle 200 200 "solid" "white"))
作业
制作一副有星星有月亮的夜空图,由于白嫖的课,属于自编题目了。
最终效果:

(require 2htdp/image)
; create a blank sketch, 400*300
(define canvas (empty-scene 400 300 "darkblue"))
; a cross star made by 2 rectangle.
(define (cross-star size1 size2 color)
(overlay (rectangle size1 size2 "solid" color)
(rectangle size2 size1 "solid" color)))
; make moon
; a full moon made by circle
(define full-moon (circle 60 "solid" "pink"))
; a circle with background-color to overlay the full moon,get a
(define cover-circle (circle 60 "solid" "darkblue"))
;put all stars and the moon to the canvas
(define pirnt-canvas
(overlay/xy (cross-star 20 5 "orange" ) -80 -200
(overlay/xy (cross-star 10 3 "gold" ) -50 -50
(overlay/xy (cross-star 30 8 "yellow" ) -230 -230
(overlay/xy (cross-star 20 8 "pink" ) -200 -100
(overlay/xy cover-circle -150 -40
(overlay/xy full-moon -180 -50
canvas)))))))
pirnt-canvas
过程
主要借助了chatGPT,通过提问发现大概的路径。
我:想要在一张画布上同时放4个不同位置不同尺寸的圆如何做?
chatGPT:
(require 2htdp/image) ; 创建一个空白画布,宽度为400,高度为400 (define canvas (empty-scene 400 400)) ; 创建四个不同尺寸和颜色的圆 (define circle1 (circle 30 "solid" "red")) (define circle2 (circle 50 "solid" "blue")) (define circle3 (circle 40 "solid" "green")) (define circle4 (circle 20 "solid" "yellow")) ; 将圆放置在不同的位置 (define canvas-with-circles (place-image circle1 50 50 (place-image circle2 70 100 (place-image circle3 250 250 (place-image circle4 350 350 canvas))))) ; 显示画布 canvas-with-circles这个是能做的。
我:能使用overlay先将这些圆定义为一个define吗?
chatGPT:
(require 2htdp/image) ; 创建四个不同尺寸和颜色的圆 (define circle1 (circle 30 "solid" "red")) (define circle2 (circle 50 "solid" "blue")) (define circle3 (circle 40 "solid" "green")) (define circle4 (circle 20 "solid" "yellow")) ; 使用overlay将四个圆叠加在一起 (define all-circles (overlay/xy circle1 -150 -150 (overlay/xy circle2 -50 -50 (overlay/xy circle3 50 50 circle4)))) ; 将所有圆放置在画布的中心 (define canvas (place-image all-circles 200 200 (empty-scene 400 400))) ; 显示画布 canvas这个也行的。
Constant Definitions
- We're going to look at how to write constant definitions to give names 我们将研究如何编写常量定义来命名
- and that those two properties-- readability and changeabiliy-- 这两个属性——可读性和可变性——
- are two of the most important properties a program can have. 是程序可以具有的两个最重要的属性。
- But for now we're just going to focus on the mechanism of constant definitions 但现在我们只关注常量定义的机制
- so that you can learn how to write a constant definition to give names 这样你就可以学习如何编写一个常量定义来命名
- to a value that you use in other parts of the program. 设置为在程序的其他部分中使用的值。
用到了一个地址 how to design programs ,白嫖意味着,得自己检索Constant这个关键字做更多的课外阅读....
(require 2htdp/image)
; . means paste a image like in word/ppt
(define XD .)
(define RXD (rotate -10 XD))
(define LXD (rotate 10 XD))
Function Definitions
感觉这个课很喜欢用图像来做定义的演示,很多别的课程更习惯用数学题来说明函数。这里还是用2htdp库。
(require 2htdp/image)
(define (bulb c)
(circle 40 "outline" c))
(above (bulb "red")
(bulb "gold")
(bulb "blue"))
(bulb (string-append "bl" "ack"))
(bulb "black")
(circle 20 "solid" "red")
总结: function是语言的核心,比较起来evaluation,funciton的parameter也可以支持operator,比如(bulb (string-append "bl" "ack")) ,除了这个多了一个function body的运行。
这部分俺也没嫖到作业,但是估计和一般的编程语言大同小异。
Booleans and if Expressions
booleans
这个视频的内容用到了上面课程大部分的内容,感觉课程设计蛮好的,符合step by step 一点点累加的教育原理。
(define WIDTH 100)
(define HEIGHT 100)
(> WIDTH HEIGHT)
;#false
(>= WIDTH HEIGHT)
;#true
(= 1 2)
;#false
(= 1 1)
;#true
(> 3 9)
;#false
(string=? "foo" "foo")
;#true
(string=? "foo" "bar")
;#false
(string=? "foo" "Foo");大小写敏感
;#false
(string=? (string=? "foo" "foo") (string=? "foo" "foo"))
;string=?: expects a string, given #true
(require 2htdp/image)
(define I1 (rectangle 10 20 "solid" "red"))
(define I2 (rectangle 20 10 "solid" "blue"))
(image-width I1)
(image-width I2)
(< (image-width I1) (image-width I2))
if expression
和Boolean关系还挺紧密,Boolean 在编程语言中,给我的感觉很像status
(if <expression1>
<expression2>
<expression3>
)
;1 question, (must produce boolean)
;2 true answer
;3 false answer
(require 2htdp/image)
(define I1 (rectangle 10 20 "solid" "red"))
(define I2 (rectangle 20 10 "solid" "blue"))
(if (< (image-width I2) (image-height I2))
"tall"
"wide"
)
; wide

- So the key thing is, the rule for if is, first you evaluate question, 所以关键是,如果的规则是,首先你评估问题,
- and then, depending on the result of the question, 然后,根据问题的结果,
- you replace the entire if with either the true answer or the false answer, 你用真答案或假答案替换整个if,
- and then you just keep evaluating. 然后你就继续评估。
<and <expr1> <expr2>...)
; all <expr> must produce BOOLEAN
; if an <expr> produces false imeediately produce false, this's called short circuiting.
; if all <expr> produce true then produce true

总结: 虽然if和booleans啥的,python,C++,JS啥的,里面都有,但是这个课程讲好细致啊....感觉又给你掰开了让你仔细观察共性。角度完全不同了......
Using the Stepper
介绍了步进器的使用,等于上一节课一点点展现流程的方式,软件自带的一个功能模块给你解决了。
鼓励在函数没有如预期工作的时候使用这个功能分析。
Discovering Primitives
介绍了两种方法帮你找到或者探索更多的语言提供的primitives,
- 瞎猜,比如已经通过一些教程知道了长方形怎么画,那么可能替换下primitives,rectangle → triangle ,说不定就可以?
- 第二种方法,可以在现在已知的primitives上,去鼠标滑中右键,
search it in help,会跳出定位到这个词的搜索列表。然后讲究一个扫描滚动扫描,这种方式的问题是,看得头晕,母语人都头晕,不要说我们老外了。
所以我觉得可以考虑尝试一下chatGPT。
我: (/ 3 4) 我想知道,有没有什么primitive 让 结果近似值为1.
chatGPT:
使用数学操作实现近似
四舍五入到最接近的整数:
使用
round函数可以将一个数四舍五入到最接近的整数。语法:
(round number)示例:
(round (/ 3 4)) ; 结果为 1向上取整:
使用
ceiling函数可以将一个数向上取整。语法:
(ceiling number)示例:
(ceiling (/ 3 4)) ; 结果为 1向下取整:
使用
floor函数可以将一个数向下取整。语法:
(floor number)示例:
(floor (/ 3 4)) ; 结果为 0最接近的整数:
使用
truncate函数可以将一个数截断为最接近的整数。语法:
(truncate number)示例:
(truncate (/ 3 4)) ; 结果为 0通过条件判断近似:
使用条件判断可以根据实际情况进行近似。
示例:
(if (> (/ 3 4) 0.5) 1 0) ; 结果为 1
总结:chatGPT可以让你更爽的学习,但不能替代学习/master 本身
Practice Problems
给了6道题
1 ⭐
#|
PROBLEM:
Write two expressions that multiply the numbers 3, 5 and 7.
The first should take advantage of the fact that * can accept more than 2 arguments.
The second should build up the result by first multiplying 3 times 5 and then multiply the result of that by 7.
|#
(* (* 3 5) 7)
2 ⭐ ⭐
给了个棋盘格,蓝黄配色。
#|
PROBLEM:
Use the DrRacket square, beside and above functions to create an image like this one:
■□
□■
If you prefer to be more creative feel free to do so. You can use other DrRacket image
functions to make a more interesting or more attractive image.
|#
;create two constants
(define COLOR1 "skyblue")
(define COLOR2 "gold")
;cube element
(define (ele color)
(rectangle 10 10 "solid" color))
;display
(above (beside(ele COLOR1)(ele COLOR2))
(beside(ele COLOR2)(ele COLOR1))
)
不过这个太简单了,决定上点强度:这个棋盘格可以自定义重复生成。

(sub1 n)的功能是把n-1,这个做法用到了递归,我感觉算超标很多了(递归问的chatGPT)
;create two constants
(define COLOR1 "skyblue")
(define COLOR2 "gold")
(define ELEWIDTH 10)
(define NUMBER 5)
;define cube‘s element
(define (ele ELEWIDTH color)
(rectangle ELEWIDTH ELEWIDTH "solid" color))
; 定义为cube
(define cube
(above (beside(ele ELEWIDTH COLOR1)(ele ELEWIDTH COLOR2))
(beside(ele ELEWIDTH COLOR2)(ele ELEWIDTH COLOR1))
))
; 横着来一排有n个cube
(define (repeat-image img n)
(if (>= 0 n)
empty-image
(beside img (repeat-image img (sub1 n)))
))
; 来n个一排
(define (repeat-row img n)
(if (>= 0 n)
empty-image
(above img (repeat-row img (sub1 n)))
))
; 棋盘格
(define all-cubes (repeat-row (repeat-image cube NUMBER) NUMBER))
all-cubes
3 ⭐
#|
PROBLEM:
Based on the two constants provided, write three expressions to determine whether:
1) IMAGE1 is taller than IMAGE2
2) IMAGE1 is narrower than IMAGE2
3) IMAGE1 has both the same width AND height as IMAGE2
|#
(define IMAGE1 (rectangle 10 15 "solid" "red"))
(define IMAGE2 (rectangle 15 10 "solid" "red"))
(> (image-height IMAGE1) (image-height IMAGE2))
(< (image-width IMAGE1) (image-width IMAGE2))
(=
(image-width IMAGE1) (image-height IMAGE2)
)
4 ⭐
#|
Given the following function definition:
(define (foo n)
(* n n))
Write out the step-by-step evaluation of the expression:
(foo (+ 3 4))
Be sure to show every intermediate evaluation step.
|#
(foo (+ 3 4))
(foo 7)
(* 7 7)
49
5 ⭐
Write a function that consumes two numbers and produces the larger of the two.
(define (bigger x y)
(if(> x y)
x
y))
(bigger 9 6)
虽然这个挺简单的,但由于格式问题,老会写成bigger(x, y)
6 ⭐
#|
Given the following function definition:
(define (foo s)
(if (string=? (substring s 0 1) "a")
(string-append s "a")
s))
Write out the step-by-step evaluation of the expression:
(foo (substring "abcde" 0 3))
Be sure to show every intermediate evaluation step.
|#
1 (foo (substring "abcde" 0 3))
2 (foo "abc")
3 (if (string=? (substring "abc" 0 1) "a")
(string-append "abc" "a")
"abc"))
4 if (string=? "a" "a")
5 if #true
6 (string-append "abc" "a")
7 "abca"
1b: How to Design Functions
这一节的内容讲比较细,上面1a讲了编程如果只有一种语言,那就是函数;这一节的核心围绕函数设计的方法,等于教你西红柿炒鸡蛋,讲讲底层逻辑,设计规范。然后希望你以后所有的素菜+肉的炒锅类都会做。
Full Speed HtDF Recipe
这个讲太快了。核心:
The HtDF recipe consists of the following steps:
- Signature, purpose and stub.
- Define examples, wrap each in check-expect.
- Template and inventory.
- Code the function body.
- Test and debug until correct
Slow Motion HtDF Recipe
这个部分是把上面一个部分的内容详细的讲一遍。
Design a function that consumes a number and produces twice that number. Call your function double. Follow the HtDF recipe and leave behind commented out versions of the stub and template.
简单说,例子是实现一个两倍返回数字的函数。即:n → 2n
step 1
Signature
这一步的目的是,明确函数的输入数据类型,和输出数据类型, 以及展示了:进一个出一个。
;;Number -> Number
目前常用的primitive Type:Number, Integer, Natural, String, Image, Boolean
Purpose
这一步是一句话介绍清楚函数的作用。
;;Number -> Number
;;produce 2 times the given number
Stub
最后会删除,但是在step1 中最好写一下,这个函数虽然简单,但是实际生产中的函数,写这一步等于磨刀不费砍柴功:
用0 是因为返回的数据类型是0. 不在这一步完成,是因为,stub主要是在test中尝试说明测试的example有没有运行(并不用确保运行成功)
;;Number -> Number
;;produce 2 times the given number
(define (double n) 0) ; stub
Stub is a function definition that:
- has correct function name
- has correct number of parameters
- produces dummy result of correct type
step 2
example
;;Number -> Number
;;produce 2 times the given number
(check-expect (double 3) 6)
(check-expect (double 5.2) 10.4)
(define (double n) 0) ; this is the stub
Example/Tests
Examples help us understand what function must do.
Multiple examples to illustrate behavior.
Warpping in check-expect means they will also serve as unit tests for the completed function.
如果此时,运行文件:
Ran 2 tests. 0 tests passed.
Check failures: Actual value 0 differs from 6, the expected value. Actual value 0 differs from 10.4, the expected value.
stub的作用这个时候才得到展示, run but failed . every step of the recipe helps with all steps after it!
step 3
Inventory - template & constants
;;Number -> Number
;;produce 2 times the given number
(check-expect (double 3) 6)
(check-expect (double 5.2) 10.4)
;(define (double n) 0) ; 只用一个; 说明最后记得删
(define (double n)
(...n))
模板等于老中的大纲,(...n) 意思是:
针对名叫double的函数传进来的参数n,将do something with n。
step 4
code body
;;Number -> Number
;;produce 2 times the given number
(check-expect (double 3) 6)
(check-expect (double 5.2) 10.4)
;(define (double n) 0) ; 只用一个; 说明最后记得删
;(define (double n) ;这个template最后也是要删掉的。
; (...n))
(define (double n)
(* 2 n))
这一步的关键是,想要完成body的书写,需要倒回去考虑看看 example的数据怎么预期的。
step 5
现在点击运行会得到成功的提示
Both tests passed!
至于没有成功,那就继续debug,直到成功。
A Simple Practice Example
这部分好像全是问题练习,然后意思是,每一个问题都建立在前一个问题的基础之上。
1. HtDF Problem
Problem: Design a function that pluralizes a given word. (Pluralize means to convert the word to its plural form.) For simplicity you may assume that just adding s is enough to pluralize a word.
;;String -> String
;;produce plural form of the given word
(check-expect (plural "pig") "pigs")
(check-expect (plural "cat") "cats")
(define (plural word)
(string-append word "s"))
2. Example - yell!
Problem:
DESIGN a function called yell that consumes strings like "hello" and adds "!" to produce strings like "hello!".
Remember, when we say DESIGN, we mean follow the recipe.
Leave behind commented out versions of the stub and template.
;; String -> String
;; add ! to the end of a string.
(check-expect (yell "bye") "bye!")
;(define (yell str) "!")
;(define (yell str)
; (...str))
(define (yell str)
(string-append str "!"))
When Tests are Incorrect
在slow motion中最后提到,test不一定总是正确,毕竟function才是编程的难点嘛。
- writing signatures and purpose statements 书写签名和目的声明
- how many tests a function should have 一个函数应该有多少个测试
- what to do when tests fail 测试失败时该怎么办
- what to do when your understanding of the purpose changes part way through the design 当您对目的的理解在设计过程中发生变化时该怎么办
Example - area
这个例子主要强调test 的编写错误的情况。
;;Number -> Number
;; produce a square's area from the given length side of square
(check-expect (area 5) 5)
(check-expect (area 6) 36)
;(define (area len)0)
;(define (area len)
; (...len))
(define (area len)
(* len len))
Ran 2 tests. 1 of the 2 tests failed.
Check failures: Actual value 25 differs from 5, the expected value.
如果example test错误,也许是因为:
- the function definition is wrong
- the test is wrong
- they are both wrong(check the test before fixing the funciton definition.)
;;Number -> Number
;; produce a square's area from the given length side of square
(check-expect (area 5) 25)
(check-expect (area 6) 36)
;(define (area len)0)
;(define (area len)
; (...len))
(define (area len)
(* len len))
Varying Recipe Order
这个例子主要是强调HtDF recipe 有些时候会改变顺序
- There is some flexibility in following the steps of the process. 遵循该过程的步骤有一定的灵活性。
- It's a structured process, but it's not a locked-in waterfall process. 这是一个结构化的流程,但不是一个锁定的瀑布流程。
Example - image-area
;; Image -> Number
;; produce image's area (w * h)
(check-expect (image-area (rectangle 2 3 "solid" "black")) (* 2 3) )
;(define (image-area img) 0)
;(define (image-area img)
;(...img))
(define (image-area img)
(* (image-width img) (image-height img)))
image-width和image-height属于在开头没加引入库说明。
(require 2htdp/image)
- 像素没有小数点,所以结果怎么乘都是整数且是正的,所类型应该是Natural
;; Image -> Natural
- 倒回去改发现signature类型没写对是很正常的。
- 忘记加库/模块 也是常见的。
Poorly Formed Problems
- Design is the process of going from a poorly formed problem to a well structured solution。设计是从一个结构不良的问题出发,到一个结构良好的解决方案的过程
- So making the problem more specific is part of the design process. 因此,使问题更加具体是设计过程的一部分。
Example - tall
这个例子重点讨论了测试集数量。
PROBLEM:
DESIGN a function that consumes an image and determines whether the image is tall.
Remember, when we say DESIGN, we mean follow the recipe.
Leave behind commented out versions of the stub and template.
how many tests does this function need? 这个功能需要多少次测试?
(require 2htdp/image)
;; Image -> Boolean
;; produce #true is the img is tall (w < h)
(check-expect (istall (rectangle 2 4 "solid" "gray")) #true)
(check-expect (istall (rectangle 4 2 "solid" "gray")) #false)
(check-expect (istall (rectangle 2 2 "solid" "gray")) #false)
;(define (istall img) #true)
;(define (istall img)
; (...img)
)
(define (istall img)
(if (< (image-width img) (image-height img))
#true
#false
)
)
感觉测试集得至少3个, 因为测试必须走完所有的代码分支+ 边界情况,在这个案例里边界是宽高相同
You realize partway through the design process that there's a boundary condition, or sometimes we call it a corner case
您在设计过程中途意识到,存在边界条件,或者有时我们称之为极端情况
There's this concept called code coverage for a test, or test coverage, which says given all my tests, how much of the code is actually being evaluated? 有一个称为测试代码覆盖率的概念,或测试覆盖率,它表示根据我的所有测试,有多少代码实际上正在评估吗?
Practice Problems
题目不多,也就3道。
1 ⭐
#|
PROBLEM:
DESIGN function that consumes a string and determines whether its length is
less than 5. Follow the HtDF recipe and leave behind commented out versions
of the stub and template.
|#
;; String -> Boolean
;; produce true if the string-length of a string less than 5
(check-expect (less5 "hello") #false)
(check-expect (less5 "hello!") #false)
(check-expect (less5 "halo") #true)
;(define (less5 str) #true); stub
;(define (less5 str) (...str)) ;templete
(define (less5 str)
(if (< (string-length str) 5)
#true
#false
)
)
2 ⭐
PROBLEM:
Use the How to Design Functions (HtDF) recipe to design a function that consumes an image,
and appears to put a box around it. Note that you can do this by creating an "outline"
rectangle that is bigger than the image, and then using overlay to put it on top of the image.
For example:
(boxify (ellipse 60 30 "solid" "red")) should produce .
Remember, when we say DESIGN, we mean follow the recipe.
Leave behind commented out versions of the stub and template.
(require 2htdp/image)
;; Image -> Image
;; produce a boxify with the given img
(check-expect (boxify (rectangle 20 30 "solid" "yellow")) (overlay (rectangle 20 30 "outline" "black") (rectangle 20 30 "solid" "yellow")))
(check-expect (boxify (ellipse 60 30 "solid" "red")) (overlay (rectangle 60 30 "outline" "black") (ellipse 60 30 "solid" "red")))
(check-expect (boxify (right-triangle 40 40 "solid" "tan")) (overlay (rectangle 40 40 "outline" "black") (right-triangle 40 40 "solid" "tan")))
(check-expect (boxify (right-triangle 30 30 "solid" "lightbrown")) (overlay (rectangle 30 30 "outline" "black") (right-triangle 30 30 "solid" "lightbrown")))
;(define (boxify img) (circle 5 "solid" "gold"))
;(define (boxify img) (...img))
(define (boxify img)
(overlay (rectangle (image-width img) (image-height img) "outline" "black") img )
)
官方的解答,2个像素的box没讲哇
;; Image -> Image
;; Puts a box around given image. Box is 2 pixels wider and taller than given image.
;; NOTE: A solution that follows the recipe but makes the box the same width and height
;; is also good. It just doesn't look quite as nice.
(check-expect (boxify (circle 10 "solid" "red"))
(overlay (rectangle 22 22 "outline" "black")
(circle 10 "solid" "red")))
(check-expect (boxify (star 40 "solid" "gray"))
(overlay (rectangle 67 64 "outline" "black")
(star 40 "solid" "gray")))
;(define (boxify i) (circle 2 "solid" "green"))
#;
(define (boxify i)
(... i))
(define (boxify i)
(overlay (rectangle (+ (image-width i) 2)
(+ (image-height i) 2)
"outline"
"black")
i))
3 ⭐
PROBLEM:
There may be more than one problem with this function design. Uncomment
the function design below, and make the minimal changes required to
resolve the error that occurs when you run it:
;; Number -> Number
;; doubles n
(check-expect (double 0) 0)
(check-expect (double 4) 8)
(check-expect (double 3.3) (* 2 3.3))
(check-expect (double -1) -2)
#;
(define (double n) 0) ; stub
(define (double n)
(* (2 n)))
;; Number -> Number
;; doubles n
(check-expect (double 0) 0)
(check-expect (double 4) 8)
(check-expect (double 3.3) (* 2 3.3))
(check-expect (double -1) -2)
;(define (double n) 0) ; stub
(define (double n)
(* 2 n))
2: How to Design Data
这周的内容我尝试更为精简和概要,因为这样速度更快,效率也更高一些。
cond Expressions
针对下面代码:
(require 2htdp/image)
;; cond-starter.rkt
(define I1 (rectangle 10 20 "solid" "red"))
(define I2 (rectangle 20 20 "solid" "red"))
(define I3 (rectangle 20 10 "solid" "red"))
;; Image -> String
;; produce shape of image, one of "tall", "square" or "wide"
(check-expect (aspect-ratio I1) "tall")
(check-expect (aspect-ratio I2) "square")
(check-expect (aspect-ratio I3) "wide")
;(define (aspect-ratio img) "") ;stub
;(define (aspect-ratio img) ;template
; (... img))
(define (aspect-ratio img)
(if (> (image-height img) (image-width img))
"tall"
(if (= (image-height img) (image-width img))
"square"
"wide")))
从if 的嵌套使用,来凸显编程语言进程中会出现的情况,当发现原本的用法,并没有很好的支撑现在的数据情况,在这个例子中,tall square wide 是相对一个层级判断的数据。就要开发出新的语法特性。
cond 很像python中的match,c/c++/javascript 中的switch case
Problem:
Given the following definition:
(define (absval n)
(cond [(> n 0) n]
[(< n 0) (* -1 n)]
[else 0]))
Hand step the execution of:
(absval -3)
解答:
;; Number -> Number
;; produce the absval of a given number, Positive, negative and zero
(check-expect (absval 3) 3)
(check-expect (absval 0) 0)
(check-expect (absval -3) 3)
(check-expect (absval -0.5) 0.5)
; (define (absval n) 0);stub
; (define (absval n)
; (...n))
(define (absval n)
(cond [(> n 0) n]
[(< n 0) (* -1 n)]
[else 0]))

cond 的stepper理解有助于知道是否采取了合适的函数来实现功能,这个很像一个个的排队,不符合就踢出去,但是一旦遇到合适的,会立即停止返回对应的value 。
(cond [(> 1 0) "yes"]
[(> -1 0) "no"]
[(= 1 0) "no"])
(cond [#true "yes"]
[(> -1 0) "no"]
[(= 1 0) "no"])
"yes"

Data Definitions
通过红绿灯的示范,说明数据和信息表达之间的关系,以及作为函数的编写来说,怎么定义,怎么关联,怎么表示,是非常重要的。通过红绿灯变换中下一个color这个函数,从ver 1 - 4 的迭代,就反映了从一开始粗糙的想法到看起来非常规范,历经的变化。
ver 1:
(define (next-color c)
(cond [(= c 0) 2]
[(= c 1) 0]
[(= c 2) 1]))
ver1 属于一看就不规范,因为没有按着之前的HTDF 格式来写。
ver 2:
;; Natural -> Natural
;; produce next color of traffic light
(check-expect (next-color 0) 2)
(check-expect (next-color 1) 0)
(check-expect (next-color 2) 1)
;(define (next-color c) 0) ;stub
;(define (next-color c) ;template
; (... c))
(define (next-color c)
(cond [(= c 0) 2]
[(= c 1) 0]
[(= c 2) 1]))
ver 2 解决了这个问题,但是还是有新的问题,比如0,1,2什么意思?
ver 3:
;; Data definitions:
;; TLColor is one of:
;; - 0
;; - 1
;; - 2
;; interp. 0 means red, 1 yellow, 2 green
#;
(define (fn-for-tlcolor c)
(cond [(= c 0) (...)]
[(= c 1) (...)]
[(= c 2) (...)]))
;; Functions
;; TLColor -> TLColor
;; produce next color of traffic light
(check-expect (next-color 0) 2)
(check-expect (next-color 1) 0)
(check-expect (next-color 2) 1)
;(define (next-color c) 0) ;stub
; Template from TLColor
(define (next-color c)
(cond [(= c 0) 2]
[(= c 1) 0]
[(= c 2) 1]))
ver3 试图解决这个问题,对 0 1 2 补充了 data definition。并且在function中 输入和输出的data type 也根据data definition进行了替换。现在唯一的问题是,0,1,2估计都得在DD的区域对着看是啥意思对不。
ver 4:
;; A small part of a traffic simulation.
;; Data definitions:
;; TLColor is one of:
;; - "red"
;; - "yellow"
;; - "green"
;; interp. "red" means red, "yellow" yellow, "green" green
#;
(define (fn-for-tlcolor c)
(cond [(string=? c "red") (...)]
[(string=? c "yellow") (...)]
[(string=? c "green") (...)]))
;; Functions
;; TLColor -> TLColor
;; produce next color of traffic light
(check-expect (next-color "red") "green")
(check-expect (next-color "yellow") "red")
(check-expect (next-color "green") "yellow")
;(define (next-color c) "red") ;stub
; Template from TLColor
(define (next-color c)
(cond [(string=? c "red") "green"]
[(string=? c "yellow") "red"]
[(string=? c "green") "yellow"]))
ver4 进行了这部分的改变,将0,1,2替换为文本,这样更降低了理解的麻烦程度。


Atomic Non-Distinct
想讲了下原则,HTDD recipe:
The first step of the recipe is to identify the inherent structure of the information. 配方的第一步是识别信息的固有结构。
Once that is done, a data definition consists of four or five elements: 完成后,数据定义由四个或五个元素组成:
- A possible structure definition (not until compound data) 可能的结构定义(直到复合数据)
- A type comment that defines a new type name and describes how to form data of that type. 定义新类型名称并描述如何形成该类型数据的类型注释。
- An interpretation that describes the correspondence between information and data. 描述信息和数据之间对应关系的解释。
- One or more examples of the data. 一个或多个数据示例。
- A template for a 1 argument function operating on data of this type. 对该类型的数据进行操作的 1 个参数函数的模板。
最重要的一点是:信息结构决定了会采用什么数据类型,进而决定了模板的结构并帮助确定example test要咋写。
HtDF With Non-Primitive Data
这节课采用了一个例子来讲解 Non-Primitive ,那可能需要先理解啥是Primitive。
Non--Primitive data: data defined by a data definition
primitive data:没data definition的情况下写function.
其实大概可以理解成,函数的入口在设计的时候,要多考虑data type,简单函数直觉就知道啥type,但是实际生产中可能一层一层的封装和指向,因此写清楚入口data type咋来的就显得比较重要了。
;; Data definitions:
;; CityName is String
;; interp. the name of a city
(define CN1 "Boston")
(define CN2 "Vancouver")
#;
(define (fn-for-city-name cn)
(... cn))
;; Template rules used: For the first part of the course
;; atomic non-distinct: String we want you to list the template
;; rules used after each template.
;;
;; Functions:
;;CityName -> Boolean
;; produce true if the given city is Godmade
(check-expect (best? "Boston") false)
(check-expect (best? "Godmade") true)
;(define (best? cn) false);stub
; took template from CityName
#;
;7 steps
(define (best? cn)
(if (string=? cn "Godmade")
true
false)
)
; 5 steps
(define (best? cn)
(string=? cn "Godmade")
)
| When the form of the information to be represented... | Use a data definition of this kind |
|---|---|
| is atomic | Simple Atomic Data |
| is numbers within a certain range | Interval |
| consists of a fixed number of distinct items | Enumeration |
| is comprised of 2 or more subclasses, at least one of which is not a distinct item | Itemization |
| consists of two or more items that naturally belong together | Compound data |
| is naturally composed of different parts | References to other defined type |
| is of arbitrary (unknown) size | self-referential or mutually referential |
HtDF X Structure of Data Orthogonality
这节课算导论,主要是强调:
数据类型可以很多种很多样,但是最后都要应用在HtDF中,也就是说,HtDF是最核心的部分,Funciton写好了可以很低成本的迁移应用到各种数据类型中。
chatGPT:
“Orthogonal” 在数学和计算机科学中,通常指的是两个对象或概念彼此独立且不相互影响。用在程序设计和开发中,指的是两个方法、流程或技术可以分别独立应用,不会彼此干扰或重叠。
Interval
[] 是左闭右开,取不到32,所以我用了33,但是课程上老师还是采用的32.
;
; PROBLEM:
;
; Imagine that you are designing a program to manage ticket sales for a
; theatre. (Also imagine that the theatre is perfectly rectangular in shape!)
;
; Design a data definition to represent a seat number in a row, where each
; row has 32 seats. (Just the seat number, not the row number.)
;
;;Data definitions:
;;SetNum is Natural[1,33]
;; interp. seat number in a row, 1 - 32.
(define SN1 1) ;aisle
(define SN2 12);middle
(define SN3 32);aisle
#;
(define (fn-4-seat-num sn)
(...sn))
;; temple rules used;
;; - atomic non-distinct: Natural[1,33]
;; funcitons:
Enumeration
带着走了一遍HtDD的文档怎么用的,比如为啥用cond? code 的条件为啥是判断string的值?多少都有些套路,不过可能因为例子太简单了,有种杀鸡用牛刀的感觉。
;
; PROBLEM:
;
; As part of designing a system to keep track of student grades, you
; are asked to design a data definition to represent the letter grade
; in a course, which is one of A, B or C.
;
;;letterGrade is one of:
;; - "A"
;; - "B"
;; - "C"
;; interp, the letter grade in a course
;;<examples are redundant for enumerations>
(define (fon-for-letter-grade lg)
(cond [(string=? lg "A") (...lg)]
[(string=? lg "B") (...lg)]
[(string=? lg "C") (...lg)]
)
)
;; template rules used:
;; - one of : 3 cases
;; - atomic distinct value:"A"
;; - atomic distinct value:"B"
;; - atomic distinct value:"C"
Itemization
据说是这周最复杂的例子,一看确实,不过这种划分方式还是有点奇妙,之前很多印象都是纯数字,因为倒计时,数字大于某个区间就是没开始,小于区间就是完了,哪这么细分三个阶段来用不同的data type 玩哟。
step1:这部分主要写了Data definition
;
; PROBLEM:
;
; Consider designing the system for controlling a New Year's Eve
; display. Design a data definition to represent the current state
; of the countdown, which falls into one of three categories:
;
; - not yet started
; - from 10 to 1 seconds before midnight
; - complete (Happy New Year!)
;
;; countdown is one of:
;; - false
;; -natural[1,10]
;; - "complete"
;;interp.
;; false means countdown has not yet started
;; Natural[1,10] : countdown is running and how many seconds
;; "complete": countdown is oer
(define cd1 false)
(define cd2 10); just started running
(define cd3 1) ; almost over
(define cd4 "complete")
step2: 开始补充data definition 的最后一部分:函数模板
(define (fn-for-countdown c)
(cond [(false? c) (...)]
[(and (number? c) (<= 1 c) (<= c 10)) (...c)]
[else (...) ])
)
;; template rules used;
;; one of 3 cases
;; atomic distinct :false
;; atomic non-distinct : Natural[1,10]
;; atomic distinct :"complete"
这里有需要强调的,主要cond 的最后一项:else
in this course we allow you to assume that a function is called with arguments that match its signature. In other programming languages this will be enforced automatically.
In this course, if you have written a well formed type comment like countdown, and you later say that a function consumes a countdown, then you can count on the function being called with a legal countdown. So what that means is when this template runs in some specific function, if C isn't false, and C isn't a number between one and 10, then C is guaranteed to be the string complete. You don't have to actually test here whether C is the string complete. What we're saying is that having taken the trouble to do type comment, and having taken the trouble to specify the signature of a function, you can count on that being respected.
在本课程中,如果你写了一个格式良好的类型注释,比如倒计时,你后来说一个函数消耗了一个倒计时,那么你可以指望被调用的函数有一个合法的倒计时。 因此,这意味着当此模板在某个特定函数中运行时,如果 C 不是假的,并且 C 不是 1 到 10 之间的数字,那幺 C 可以保证是字符串完成的。你不必在这里实际测试C是否是完整的字符串。 我们要说的是,在不厌其烦地进行类型注释,并且不厌其烦地指定函数的签名之后,您可以指望这一点得到尊重。
The reason that's a reasonable thing to do in this course is the other programming languages that you will use is a part of the programming language implementation call the compiler, which will actually enforce that rule to make sure that it's always true. So it's a reasonable rule for you to start counting on here.
在本课程中,这样做的原因是,您将使用的其他编程语言是编程语言实现的一部分,称为编译器,编译器实际上将执行该规则以确保它始终为真。 因此,从这里开始依赖这是一个合理的规则。
it is actually just a part of the compiler called the type checker, And it doesn't have to be part of the compiler. And there are several other caveats. But the key point is that many languages enforce rules about function arguments matching the funcion signature.
step3: 最后部分强调 guard
Rules:
1. if a given subclass is the last subclass of its type, we can reduce the test to just the guard. ie(number? c)
2. if alll remianing subclasses are of the same type, then we can eliminate all of the guards.
guard可以理解成类型判断,边界,前置条件,就是说也不一定啥时候都要guard,看情况来。毕竟省一步程序就快一步。
HtDF with Interval
开始用区间数据演示设计函数了,例子比较简单,但是and or 这两个关键字语法已经讲了算是。
;
; PROBLEM:
;
; Using the SeatNum data definition below design a function
; that produces true if the given seat number is on the aisle.
;
;; Data definitions:
;; SeatNum is Natural[1, 32]
;; Interp. Seat numbers in a row, 1 and 32 are aisle seats
(define SN1 1) ;aisle
(define SN2 12) ;middle
(define SN3 32) ;aisle
#;
(define (fn-for-seat-num sn)
(... sn))
;; Template rules used:
;; atomic non-distinct: Natural[1, 32]
;; Functions:
;;setNum -> Boolean
;; prduce true if the given number in the aisle
(check-expect (aisle? 33) false)
(check-expect (aisle? 1) true)
(check-expect (aisle? 32) true)
(check-expect (aisle? 16) false)
(check-expect (aisle? 0) false)
;(define (aisle? sn) false);stub
;< use templete from setNum>
(define (aisle? sn)
(or (= sn 1)
(= sn 32))
)
HtDF with Enumeration
用这个例子,主要就是说明,枚举的测试example不用多写,因为你写funciton的时候,基本枚举过了(很难说枚举类型还需不需要写用例)
哎,这周内容也太乏味了......
;
; PROBLEM:
;
; Using the LetterGrade data definition below design a function that
; consumes a letter grade and produces the next highest letter grade.
; Call your function bump-up.
;
;; Data definitions:
;; LetterGrade is one of:
;; - "A"
;; - "B"
;; - "C"
;; interp. the letter grade in a course
;; <examples are redundant for enumerations>
#;
(define (fn-for-letter-grade lg)
(cond [(string=? lg "A") (...)]
[(string=? lg "B") (...)]
[(string=? lg "C") (...)]))
;; Template rules used:
;; one-of: 3 cases
;; atomic distinct: "A"
;; atomic distinct: "B"
;; atomic distinct: "C"
;; Functions:
;; LetterGrade -> LetterGrade
;; produce next highest letter grade (no change for A)
(check-expect (bump-up "A") "A")
(check-expect (bump-up "B") "A")
(check-expect (bump-up "C") "B")
;(define (bump-up lg) "A");stub
; <use template from LetterGrade>
(define (bump-up lg)
(cond [(string=? lg "A") "A"]
[(string=? lg "B") "A"]
[(string=? lg "C") "B"]))
HtDF with Itemization
把之前有个倒计时的问题拿来详细做,(number->string 5) 这类自带语法属于根本不介绍了......(毕竟这个课不是主要讲语法的)
;; countdown-to-display-starter.rkt
;
; PROBLEM:
;
; You are asked to contribute to the design for a very simple New Year's
; Eve countdown display. You already have the data definition given below.
; You need to design a function that consumes Countdown and produces an
; image showing the current status of the countdown.
;
(require 2htdp/image)
;; Data definitions:
;; Countdown is one of:
;; - false
;; - Natural[1, 10]
;; - "complete"
;; interp.
;; false means countdown has not yet started
;; Natural[1, 10] means countdown is running and how many seconds left
;; "complete" means countdown is over
(define CD1 false)
(define CD2 10) ;just started running
(define CD3 1) ;almost over
(define CD4 "complete")
#;
(define (fn-for-countdown c)
(cond [(false? c) (...)]
[(and (number? c) (<= 1 c) (<= c 10)) (... c)]
[else (...)]))
;; Template rules used:
;; - one of: 3 cases
;; - atomic distinct: false
;; - atomic non-distinct: Natural[1, 10]
;; - atomic distinct: "complete"
;; Functions:
;; CountDown -> Image
;; produce nice image of current state of countdown
(check-expect (countdown->image false) (square 20 "outline" "black"))
(check-expect (countdown->image 5) (text (number->string 5) 24 "black"))
(check-expect (countdown->image "complete") (text "happy new year!" 24 "red"))
;(define (countdown->image c) (square 20 "outline" "black"));stub
; <templete from Countdown>
(define (countdown->image c)
(cond [(false? c) (square 20 "outline" "black")]
[(and (number? c) (<= 1 c) (<= c 10)) (text (number->string c) 24 "black")]
[else (text "happy new year!" 24 "red")]))
主要容易犯的错:
- 没有引入库
(require 2htdp/image) countdown->image这种命名方式是BSL的规范,每个语言都有偏好的规范。- dr.racket 也有全文替换,但是不会替换掉注释的内容,也就是说,得手动修改。
Structure of Information Flows Through
本周总结开始了.....
- week2 主要讲了红色部分
- week1 主要讲了蓝色部分
- week3 要搞定 how to design world,也就是绿色部分。
primitive mix non-primitive是常态,交叉一下就得出复杂的世界。
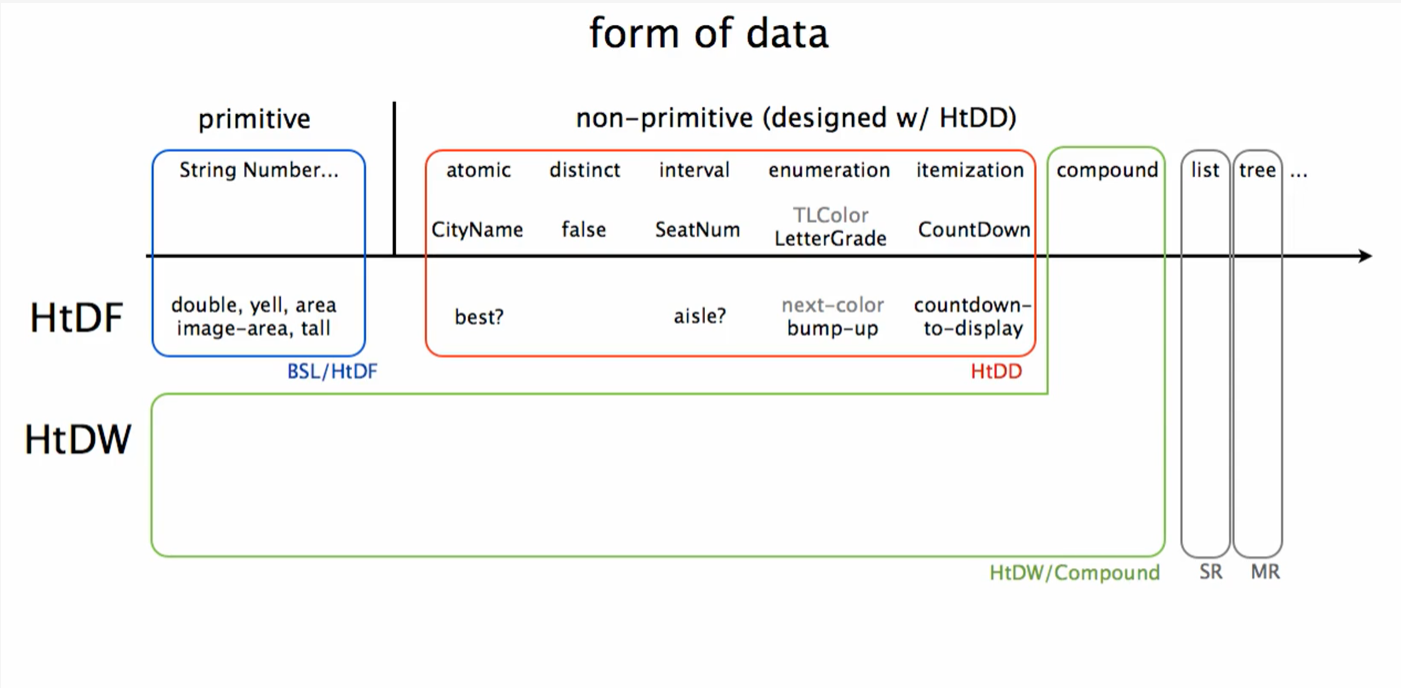
回顾了本周的各种例子,代码结构上呈现出非常有结构的样子,而且从数据设计到功能设计,到测试,都是独立但互相交叉影响。structure还是非常重要。
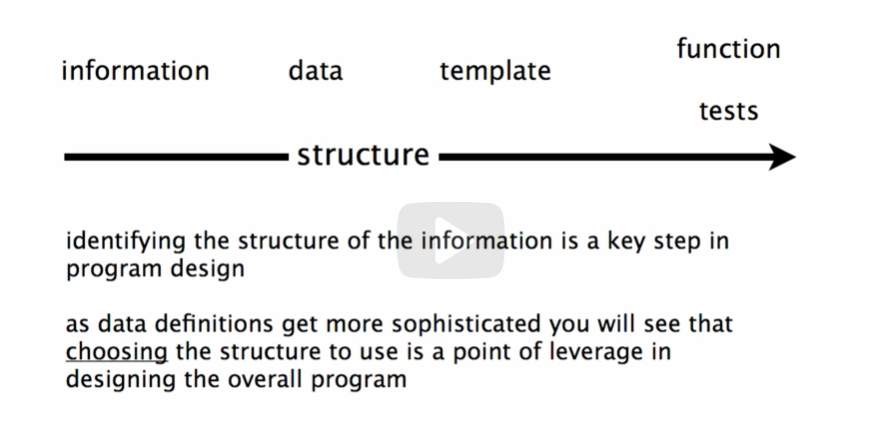
强调了,数据结构驱动模板在大多数时候编程都管用,好好用事半功倍。
week3 将更多考虑控制结构来主导的function设计,但即便这样,数据形式还是很重要。因为信息决定数据,数据决定函数形式。
Practice Problems
1 ⭐
;; demolish-starter.rkt
;; =================
;; Data definitions:
;
; PROBLEM A:
;
; You are assigned to develop a system that will classify
; buildings in downtown Vancouver based on how old they are.
; According to city guidelines, there are three different classification levels:
; new, old, and heritage.
;
; Design a data definition to represent these classification levels.
; Call it BuildingStatus.
;
;; =================
;; Functions:
;
; PROBLEM B:
;
; The city wants to demolish all buildings classified as "old".
; You are hired to design a function called demolish?
; that determines whether a building should be torn down or not.
;
;; =================
;; Data definitions:
;;BuildingStatus is one of:
;; - "new"
;; - "old"
;; - "heritage"
;; interp.
(define BS1 "new")
(define BS2 "old")
(define BS3 "heritage")
#;
(define (fn-for-building-status bs)
(if(string=? bs "old")
(...)
(...))
)
;; Template rules used:
;; - atomic non-distinct: "new","old","heritage"
;; =================
;; Functions:
;; BuildingStatus -> Boolean
(check-expect (demolish "new") "not torn down")
(check-expect (demolish "old") "torn down")
(check-expect (demolish "heritage") "not torn down")
;(define (demolish bs) "new");stub
;< templete from BuildingStatus>
(define (demolish bs)
(if(string=? bs "old")
"torn down"
"not torn down")
)
2 ⭐⭐
PROBLEM A:
You are designing a program to track a rocket's journey as it descends
100 kilometers to Earth. You are only interested in the descent from
100 kilometers to touchdown. Once the rocket has landed it is done.
Design a data definition to represent the rocket's remaining descent.
Call it RocketDescent.
PROBLEM B:
Design a function that will output the rocket's remaining descent distance
in a short string that can be broadcast on Twitter.
When the descent is over, the message should be "The rocket has landed!".
Call your function rocket-descent-to-msg.
;; Data definitions:
;; RocketDescent is one of:
;; - false
;; - Number[0, 100]
;; - "The rocket has landed!"
;; interp.
;; false means rocket's 100km journey didn't start.
;; Number[0, 100] means How many meters did the rocket fall
;; "The rocket has landed!" means the rocket has landed
(define RD1 false)
(define RD2 99) ;almost over
(define RD3 0.1) ;just started falling 0.1 km
(define RD4 "The rocket has landed!")
#;
(define (fn-for-RocketDescent d)
(cond [(false? d) (...)]
[(and (number? d) (> d 0) (< d 100)) (... d)]
[else (...)]))
;; Template rules used:
;; - one of: 3 cases
;; - atomic distinct: false
;; - atomic non-distinct: Number[0, 100]
;; - atomic distinct: "The rocket has landed!"
;; =================
;; Functions:
;; RocketDescent -> String
(check-expect (rocket-descent-to-msg false) "ready")
(check-expect (rocket-descent-to-msg 100) "The rocket has landed!")
(check-expect (rocket-descent-to-msg 5) "The rocket is still 95.0km away from landing")
(check-expect (rocket-descent-to-msg 78.2) "The rocket is still 21.8km away from landing")
(check-expect (rocket-descent-to-msg 99.599) "The rocket is still 0.401km away from landing")
;(define (rocket-descent-to-msg d) false);stub
; < templete from RocketDescent>
(define (rocket-descent-to-msg d)
(cond [(false? d) "ready"]
[(and (number? d) (> d 0) (< d 100))
(string-append "The rocket is still " (number->string (exact->inexact (- 100 d) )) "km away from landing")]
[else "The rocket has landed!"])
)
还是有点麻烦,主要是展示问题,number->string得到的可能是分数,但是一般来说,用户习惯看小数,所以还需要用exact->inexact 转成浮点数。
这个和标准答案出入还是有点大,主要是意思理解反了,不过听众角度,掉了多少km不重要,距离落地还有多少km比较重要。
(define RD1 100)
(define RD2 40)
(define RD3 0.5)
(define RD4 false)
#;
(define (fn-for-rocket-descent rd)
(cond [(and (number? rd)
(< 0 rd)
(<= rd 100))
(... rd)]
[else (...)]))
;; Template Rules Used:
;; - one of: 2 cases
;; - atomic non-distinct: Number[100, 0)
;; - atomic distinct: false
;; RocketDescent -> String
;; outputs a Twitter update on rocket's descent distance
(check-expect (rocket-descent-to-msg 100) "Altitude is 100 kms.")
(check-expect (rocket-descent-to-msg 40) "Altitude is 40 kms.")
(check-expect (rocket-descent-to-msg .5) "Altitude is 1/2 kms.")
(check-expect (rocket-descent-to-msg false) "The rocket has landed!")
;(define (rocket-descent-to-msg rd) "") ;stub
; <template from RocketDescent>
(define (rocket-descent-to-msg rd)
(cond [(and (number? rd)
(< 0 rd)
(<= rd 100))
(string-append "Altitude is " (number->string rd) " kms.")]
[else
"The rocket has landed!"]))
Quiz
week2的quiz 给了我们白嫖党
;; HtDD Design Quiz
;; Age is Natural
;; interp. the age of a person in years
(define A0 18)
(define A1 25)
#;
(define (fn-for-age a)
(... a))
;; Template rules used:
;; - atomic non-distinct: Natural
; Problem 1:
;
; Consider the above data definition for the age of a person.
;
; Design a function called teenager? that determines whether a person
; of a particular age is a teenager (i.e., between the ages of 13 and 19).
; Problem 2:
;
; Design a data definition called MonthAge to represent a person's age
; in months.
; Problem 3:
;
; Design a function called months-old that takes a person's age in years
; and yields that person's age in months.
;
; Problem 4:
;
; Consider a video game where you need to represent the health of your
; character. The only thing that matters about their health is:
;
; - if they are dead (which is shockingly poor health)
; - if they are alive then they can have 0 or more extra lives
;
; Design a data definition called Health to represent the health of your
; character.
;
; Design a function called increase-health that allows you to increase the
; lives of a character. The function should only increase the lives
; of the character if the character is not dead, otherwise the character
; remains dead.
; Problem 1:
;; Age -> Boolean
;; produce true if the given age is between of 13 and 19
(check-expect (teenager? 15) true)
(check-expect (teenager? 12) false)
(check-expect (teenager? 20) false)
;(define (teenager? a) true);stub
;<templete from Age>
(define (teenager? a)
(and (number? a)
(<= a 19)
(>= a 13))
)
; Problem 2:
;; data definition:
;; MonthAge is Natural
;; interp. the age of a person in months
(define M0 60) ; a person in 60months means 5 years old
(define M1 72) ; a person in 60months means 6 years old
(define M2 78) ; a person in 60months means 6 years old
#;
(define (fn-for-MonthAge m)
(... m))
;; Template rules used:
;; - atomic non-distinct: Natural
; Problem 3:
;; Age -> MonthAge
;; produce monthage of the given age
(check-expect (months-old 3) 36)
(check-expect (months-old 12) 144)
(check-expect (months-old 11) 132)
;(define (months-old y) (* y 12));stub
;<templete from MonthAge>
(define (months-old y)
(* y 12))
; Problem 4:
;; data definition:
;; Health is one of:
;; - false
;; - Natural
;;interp.
;; - false means dead
;; - Natural means alive line is 0 or more
;; the age of a person in months
(define H1 false)
(define H2 12)
(define H3 0 )
#;
(define (fn-for-Health h)
(... h))
;; Template rules used:
;; - one of: 3 cases
;; - atomic distinct: false
;; - atomic distinct: Natural
;; =================
;; Functions:
;; Health -> Health
;; add lives when alived, add livers is unuseful when dead.
(check-expect (increase-health false 14) false)
(check-expect (increase-health 5 14) 19)
;(define (increase-health h ih) false );stub
;< templete from Health>
(define (increase-health h ih)
(cond [(false? h) false]
[(number? h) (+ h ih)]))
3a: How to Design Worlds
这部分老师坦言,要开始写交互程序了,动画啥的。会比之前的内容有趣。
顺便总结了一下之前的学习内容:
- You've learned about different forms of primitive data like numbers and strings and images.
- You've learned about expressions like if and cond,
- how to define functions and constants, the rules for evaluating BSL code.
- We've also learned how to design functions recipe, and how to design data recipe, and how to use the data-driven template rules.
Interactive Programs
强调了了虽然有趣了一些,但是也不会太吊,因为计算机图形学要太多复杂的数学知识了。
属于是降低过高的预期了,然后结尾预告会实现一个单行的文本输入功能,类似发短信那个打字框。
The big-bang Mechanism
重点讲了机制在交互程序中的运行逻辑:changing state,changing display,keyboard and/or mouse affects behavior。
举例的动画,感觉很像scratch
主要涉及介绍了新的expressionplace-image,感觉之前我已经自己用过不少了。
整个一小节全部在以一个程序来讲解在干啥,做了啥,big-bang 每一步咋运行啥,介绍了big-bang这个名字的栓双关:把碎片揉在一起,然后bang 产出一个world。
总的来说,讲课逻辑和之前两周非常像。

1. Domain Analysis
基于recipe的例子来讲,这部分主要是前期分析,磨刀不费砍材工。
Domain Analysis 阶段要点是:
- sketch
- identify constant information
- identify changing information
- identify big-bang option
给出了一些big-bang 选项关键词表
| If your program needs to: | Then it needs this option: |
|---|---|
| change as time goes by (nearly all do) | on-tick |
| display something (nearly all do) | to-draw |
| change in response to key presses | on-key |
| change in response to mouse activity | on-mouse |
| stop automatically | stop-when |
PROBLEM:
Use the How to Design Worlds recipe to design an interactive
program in which a cat starts at the left edge of the display
and then walks across the screen to the right. When the cat
reaches the right edge it should just keep going right off
the screen.
Once your design is complete revise it to add a new feature,
which is that pressing the space key should cause the cat to
go back to the left edge of the screen. When you do this, go
all the way back to your domain analysis and incorporate the
new feature.
To help you get started, here is a picture of a cat, which we
have taken from the 2nd edition of the How to Design Programs
book on which this course is based.
| constant info | changing info | big-bang option |
|---|---|---|
| width of the screen | the cat's x-coordinate is changing | on-tick |
| height of the screen | to-draw |
|
| the cat's y-coordinate doesn't change.: center-y | ||
| the(0,0) has been identified in the upper left corner | ||
| background image : MTS (empty scene) | ||
| cat-image |
做完这上面的分析,下一步就需要将其转换为代码。
2. Program through main Function
Build the actual program阶段来临啦:
- Constants (based on 1.2 above)
- Data definitions using HtDD (based on 1.3 above)
- Functions using HtDF
- main first (based on 1.3, 1.4 and 2.2 above)
- wish list entriesfor big-bang handlers
- Work through wish list until done
Template for a World Program
这节课给的模板,已经不是视频介绍了,而是给了url,说明用别人写好的模板/代码 没啥问题,问题是要知道该用就要用,以及用啥。
又一次强调了,模板不是只给初学者用得,反而越是复杂的功能设计用得越多。
(require 2htdp/image)
(require 2htdp/universe)
;; My world program (make this more specific)
;; =================
;; Constants:
;; =================
;; Data definitions:
;; WS is ... (give WS a better name)
;; =================
;; Functions:
;; WS -> WS
;; start the world with ...
;;
(define (main ws)
(big-bang ws ; WS
(on-tick tock) ; WS -> WS
(to-draw render) ; WS -> Image
(stop-when ...) ; WS -> Boolean
(on-mouse ...) ; WS Integer Integer MouseEvent -> WS
(on-key ...))) ; WS KeyEvent -> WS
;; WS -> WS
;; produce the next ...
;; !!!
(define (tock ws) ...)
;; WS -> Image
;; render ...
;; !!!
(define (render ws) ...)
对照着1中的表格,完成了常量的编写。
;; =================
;; Constants:
(define WIDTH 600)
(define HEIGHT 400)
(define CTR-Y (/ HEIGHT 2))
(define MTS (empty-scene WIDTH HEIGHT "white") ) ; give a white background.
(define CAT-IMG .)
Now, let me reinforce the point I made before about using the constants-- always referring to the constants. Notice that this code that I have here lines up really well with the analysis we did.The fact that I can look at the analysis and look at the code and understand where everything in the analysis showed up in the code is a thing called traceability.
现在,让我强调一下我之前提出的关于使用常量的观点——总是指常量。请注意,我在这里的这段代码与我们所做的分析非常吻合。事实上,我可以查看分析并查看代码并了解分析中的所有内容在代码中显示的位置,这称为可追溯性。
And that is this is an important intuition. The way to think about is there's only two kinds of programs in the world. There's program that the change and programs that nobody uses. Put it another way, any program that anybody uses is always changing. People always want it to do more and better things.
这是一个重要的直觉。思考的方式是,世界上只有两种程序。有更改的程序和没人用的程序。换句话说,任何人使用的任何程序总是在变化。人们总是希望它做更多更好的事情。
然后对照1中的changing info 做了data definition,能用常量用常量。
;; =================
;; Data definitions:
;; CAT-X is a Number
;; interp. x position of the cat in screen coordinates.
(define X1 0);left edge
(define X2 (/ WIDTH 2));MIDDLE
(define X3 WIDTH);right edge
#;
(define (fn-for-cat x)
(...x))
;; Templete rules used:
;; - atomic non-distinct :Number
接着,要开始写框架,一就要对照1中的分析:
;; =================
;; Functions:
;; CAT-X -> CAT-X
;; start the world with ...
;;
(define (main x)
(big-bang x ; CAT-X
(on-tick advance-cat ) ; CAT-X -> CAT-X
(to-draw render))) ; CAT-X -> Image
;; CAT-X -> CAT-X
;; produce the next cat, by advancing it one pixel to right.
;; !!!
(define (advance-cat x) 0)
;; CAT-X -> Image
;; render the cat image at appropriate place on MTS
;; !!!
(define (render x) MTS)
A wish-list entry has a signature,purpose,!!! and a stub.
It is a promise to come back and finish this function later.
In bigger programs you can have 10s or 100s of pending wish list entries, so it pays to be disciplined about writing down what you need to do
!!! 强烈的表明,没写完,记得回来干活。
3.Working through the Wish List
这一步就是遵循HtDF完善每个小函数。这是这个程序的第一个版本。
;; =================
;; Functions:
;; CAT-X -> CAT-X
;; start the world with (main 0)
;;
(define (main x)
(big-bang x ; CAT-X
(on-tick advance-cat ) ; CAT-X -> CAT-X
(to-draw render))) ; CAT-X -> Image
;; CAT-X -> CAT-X
;; produce the next cat, by advancing it one pixel to right.
(check-expect (advance-cat 3)4)
;(define (advance-cat x) 0) ;stub
;;< templete form the CAT-X>
(define (advance-cat x)
(+ x 1))
;; CAT-X -> Image
;; render the cat image at appropriate place on MTS
(check-expect (render 4) (place-image CAT-IMG 4 CTR-Y MTS))
(define (render x)
(place-image CAT-IMG x CTR-Y MTS)
)
4. Improving a World Program - Add SPEED
增加了常量SPEED,并且强调了可以用到check-expects里,会更清楚也更容易修改。
(require 2htdp/image)
(require 2htdp/universe)
;; a cat that walks from left to right across the screen.
;; =================
;; Constants:
(define WIDTH 600)
(define HEIGHT 400)
(define CTR-Y (/ HEIGHT 2))
(define MTS (empty-scene WIDTH HEIGHT "white") ) ; give a white background.
(define CAT-IMG .)
;; add speed
(define SPEED 10)
;; =================
;; Data definitions:
;; CAT-X is a Number
;; interp. x position of the cat in screen coordinates.
(define X1 0);left edge
(define X2 (/ WIDTH 2));MIDDLE
(define X3 WIDTH);right edge
#;
(define (fn-for-cat x)
(...x))
;; Templete rules used:
;; - atomic non-distinct :Number
;; =================
;; Functions:
;; CAT-X -> CAT-X
;; start the world with (main 0)
;;
(define (main x)
(big-bang x ; CAT-X
(on-tick advance-cat ) ; CAT-X -> CAT-X
(to-draw render))) ; CAT-X -> Image
;; CAT-X -> CAT-X
;; produce the next cat, by advancing it SPEED(s) pixel to right.
(check-expect (advance-cat 3)(+ 3 SPEED))
;(define (advance-cat x) 0) ;stub
;;< templete form the CAT-X>
(define (advance-cat x)
(+ x SPEED))
;; CAT-X -> Image
;; render the cat image at appropriate place on MTS
(check-expect (render 4) (place-image CAT-IMG 4 CTR-Y MTS))
(define (render x)
(place-image CAT-IMG x CTR-Y MTS)
)
Good designer are able to use a wide variety of models when working on programs.
Some models are simple informal models like this one. Some are complex and quite mathematical. Most are somewhere in between.
优秀的设计师在编写进程时能够使用各种各样的模型。
有些模型是简单的非正式模型,就像这个模型一样。有些很复杂,而且相当数学化。大多数介于两者之间。
working hard to make the structure of the program match the structure of the analysis made it really easy to go back and make this change, because the analysis became kind of a model of the program. And we could think about what we needed to do the program first at the model level, first using this analysis picture, and then quickly run through the program catching it up to the new analysis. This ability to work on programs by reasoning about them at a model level is one of the things that really separates program designers for people
5. Improving a World Program - Add key handler
只在4的基础上对function部分进行了一些追加。
;; =================
;; Functions:
;; CAT-X -> CAT-X
;; start the world with (main 0)
;;
(define (main x)
(big-bang x ; CAT-X
(on-tick advance-cat ) ; CAT-X -> CAT-X
(to-draw render) ; CAT-X -> Image
(on-key handle-key))) ; CAT-X KeyEvent -> CAT-X
;; CAT-X -> CAT-X
;; produce the next cat, by advancing it SPEED(s) pixel to right.
(check-expect (advance-cat 3)(+ 3 SPEED))
;(define (advance-cat x) 0) ;stub
;;< templete form the CAT-X>
(define (advance-cat x)
(+ x SPEED))
;; CAT-X -> Image
;; render the cat image at appropriate place on MTS
(check-expect (render 4) (place-image CAT-IMG 4 CTR-Y MTS))
(define (render x)
(place-image CAT-IMG x CTR-Y MTS)
)
;; CAT-X KeyEvent -> CAT-X
;; reset cat to left edge when space key is pressed
(check-expect (handle-key 10 " ") 0)
(check-expect (handle-key 10 "a") 10)
(check-expect (handle-key 0 " ") 0)
;; argu1 is x of cat, argu2 is keybutton
;(define (handle-key x ke) 0); stub
;; < templete form the HtDF page >
(define (handle-key x ke)
(cond [(key=? ke " ") 0]
[else
x]))
6.Improving a World Program :add new feature
在5的基础上,给了一个追加需求:当鼠标点击页面的时候,cat 去到鼠标的位置。
1 通过取余让猫自动回到画布左边边缘。
等于循环了猫的x坐标,在0-600这个区间。
;;< templete form the CAT-X>
(define (advance-cat x)
(modulo (+ x SPEED) WIDTH)
)
2 先只移动到鼠标的x上,cat依旧在页面中间
main函数中追加on-mouse事件,编写对应的handle-mouse 函数。当按下鼠标左键button-down 返回鼠标的x坐标,否则依旧是猫的坐标x。
(define (main x )
(big-bang x ; CAT-X
(on-tick advance-cat ) ; CAT-X -> CAT-X
(to-draw render) ; CAT-X -> Image
(on-key handle-key) ; CAT-X KeyEvent -> CAT-X
(on-mouse handle-mouse))) ; CAT-X MouseEvent -> CAT-X
;; CAT-X MouseEvent -> CAT-X
;; made cat go to the situation of mouse's x and y
(define (handle-mouse x mouse-x mouse-y event)
(cond [(mouse=? event "button-down") mouse-x]
[else
x]))
3 cat也移动到鼠标的y坐标上。
需要的改动比较大,data definition得改,想要 cat(x,y) 这样的结构。
先了解一下 struct 在BSL里咋用的:
;; Data definitions:
;; 1. 定义结构
(define-struct cat (x y))
;; 2. 创建结构的实例
(define c1 (make-cat 3 4))
(define c2 (make-cat 7 1))
;; 3. 访问字段
(cat-x c1) ; 结果是 3
(cat-y c1) ; 结果是 4
;; 4. 修改字段
(define c3 (make-cat (cat-x c1) (+ (cat-y c1) 10))) ; c3 是 (3, 14)
;; 显示结果
c1 ; 显示 (make-cat 3 4)
c2 ; 显示 (make-cat 7 1)
c3 ; 显示 (make-cat 3 14)
改写原本的:
(require 2htdp/image)
(require 2htdp/universe)
;; a cat that walks from left to right across the screen.
;; =================
;; Constants:
(define WIDTH 600)
(define HEIGHT 400)
(define MTS (empty-scene WIDTH HEIGHT "white") ) ; give a white background.
(define CAT-IMG .)
;; add speed
(define SPEED 10)
;; cat's init
(define INITIAL-X 0)
(define INITIAL-Y (/ HEIGHT 2))
;; =================
;; Data definitions:
;; CAT is the cat in screen coordinates
(define-struct cat (x y))
(define INITIALCAT (make-cat INITIAL-X INITIAL-Y))
#;
(define (fn-for-cat cat)
(...))
;; Templete rules used:
;; - atomic distinct :struct(Number,Number)
;; Functions:
;; CAT -> CAT
;; start the world with (main )
;;
(define (main INITIALCAT)
(big-bang INITIALCAT ; CAT
(on-tick advance-cat ) ; CAT -> CAT
(to-draw render) ; CAT -> Image
(on-key handle-key))) ; CAT- KeyEvent -> CAT
;; CAT -> CAT
;; produce the next cat, by advancing it SPEED(s) pixel to right.
;(define (advance-cat cat) 0) ;stub
;;< templete form the CAT>
(define (advance-cat cat)
(make-cat (modulo (+ (cat-x cat) SPEED) WIDTH) (cat-y cat))
)
;; CAT-> Image
;; render the cat image at appropriate place on MTS
(define (render cat)
(place-image CAT-IMG (cat-x cat) (cat-y cat) MTS)
)
;; CAT KeyEvent -> CAT
;; reset cat to left edge when space key is pressed
;; < templete form the HtDF page >
(define (handle-key cat ke)
(cond [(key=? ke " ") (make-cat 0 (cat-y cat))]
[else
cat]))
增加鼠标的:
(require 2htdp/image)
(require 2htdp/universe)
;; a cat that walks from left to right across the screen.
;; =================
;; Constants:
(define WIDTH 600)
(define HEIGHT 400)
(define MTS (empty-scene WIDTH HEIGHT "white") ) ; give a white background.
(define CAT-IMG .)
;; add speed
(define SPEED 10)
;; cat's init
(define INITIAL-X 0)
(define INITIAL-Y (/ HEIGHT 2))
;; =================
;; Data definitions:
;; CAT is the cat in screen coordinates
(define-struct cat (x y))
(define INITIALCAT (make-cat INITIAL-X INITIAL-Y))
#;
(define (fn-for-cat cat)
(...))
;; Templete rules used:
;; - atomic non-distinct :Number
;; Functions:
;; CAT -> CAT
;; start the world with (main )
;;
(define (main INITIALCAT)
(big-bang INITIALCAT ; CAT
(on-tick advance-cat ) ; CAT -> CAT
(to-draw render) ; CAT -> Image
(on-key handle-key) ; CAT- KeyEvent -> CAT
(on-mouse handle-mouse))) ; CAT MouseEvent -> CAT
;; CAT -> CAT
;; produce the next cat, by advancing it SPEED(s) pixel to right.
;(define (advance-cat cat) 0) ;stub
;;< templete form the CAT>
(define (advance-cat cat)
(make-cat (modulo (+ (cat-x cat) SPEED) WIDTH) (cat-y cat))
)
;; CAT-> Image
;; render the cat image at appropriate place on MTS
(define (render cat)
(place-image CAT-IMG (cat-x cat) (cat-y cat) MTS)
)
;; CAT KeyEvent -> CAT
;; reset cat to left edge when space key is pressed
;; < templete form the HtDF page >
(define (handle-key cat ke)
(cond [(key=? ke " ") (make-cat 0 (cat-y cat))]
[else
cat]))
;; CAT MouseEvent -> CAT
;; made cat go to the situation of mouse's x and y
(define (handle-mouse cat mouse-x mouse-y event)
(cond [(mouse=? event "button-down") (make-cat mouse-x mouse-y)]
[else
cat]))
Practice Problems
1 ⭐⭐
PROBLEM:
Design an animation of a simple countdown.
Your program should display a simple countdown, that starts at ten, and decreases by one each clock tick until it reaches zero, and stays there.
To make your countdown progress at a reasonable speed, you can use the rate option to on-tick. If you say, for example, (on-tick advance-countdown 1) then big-bang will wait 1 second between calls to advance-countdown.
Remember to follow the HtDW recipe! Be sure to do a proper domain analysis before starting to work on the code file.
Once you are finished the simple version of the program, you can improve it by reseting the countdown to ten when you press the spacebar.
| constant info | changing info | big-bang option |
|---|---|---|
| STARTNUM 10 | number sub 1 after 1 gaptime | on-tick |
| GAPTIME 1 | to-draw |
|
| STOPNUM 0 | stop-when |
|
| screen 200 *100 |
(require 2htdp/image)
(require 2htdp/universe)
;; countDown
;; =================
;; Constants:
(define STARTNUM 10) ;the start number
(define GAPTIME 1) ; the gap time between the number's change
(define STOPNUM 0) ; the end number
(define WIDTH 200)
(define HEIGHT 100)
(define MTS (empty-scene WIDTH HEIGHT "white") ) ; give a white background.
;; =================
;; Data definitions:
;; countdown is a Numer
;; interp. countdown
(define cd1 10) ;countdown started
(define cd2 5) ; middle
(define cd3 0) ; end
#;
(define (fn-for-countdown cd)
(...cd))
;; Templete rules used:
;; - atomic non-distinct Number
;; =================
;; Functions:
;; countdown -> countdown
;; start the world with (main STARTNUM)
;;
(define (main cd)
(big-bang cd ; countDown
(on-tick coutdown GAPTIME) ; countDown -> countDown
(to-draw render) ; countDown -> Image
(stop-when stopCD) ; CountDown -> boolean.
(on-key handle-key) ; countDown -> countDown
))
;; countDown -> countDown
;; produce the next number by sub 1
(check-expect (coutdown 5) (- 5 1))
;(define (coutdown cd) 0 ) ;stub
;;<templete from countDown>
(define (coutdown cd)
(- cd 1))
;; countDown -> Image
;; render the num on screen
(check-expect (render 5) (place-image (text "5" 24 "blue") (/ WIDTH 2) (/ HEIGHT 2) MTS))
;(define (render cd) 0) ;stub
;;<templete from countDown>
(define (render cd)
(place-image (text (number->string cd) 24 "blue") (/ WIDTH 2) (/ HEIGHT 2) MTS)
)
;; countDown -> boolean.
;; if cd num = 0 ,stop countdown process
(check-expect (stopCD 1) false)
(check-expect (stopCD 0) false)
;(define (stopCD cd) 0) ;stub
;;<templete from countDown>
(define (stopCD cd)
(if (< cd 0)
true
false)
)
;;countDown -> countDown
;; reset number to STARTNUM when space key is pressed
;(check-expect (handle-key 1) 10)
;(check-expect (handle-key 0) 10)
;(define (handle-key cd) STARTNUM); stub
;;<templete from countDown>
(define (handle-key cd ke)
(cond [(key=? ke " ") STARTNUM]
[else
cd]))
2 ⭐⭐
PROBLEM:
Design an animation of a traffic light.
Your program should show a traffic light that is red, then green, then yellow, then red etc. For this program, your changing world state data definition should be an enumeration.
Here is what your program might look like if the initial world state was the red traffic light:
To make your lights change at a reasonable speed, you can use the rate option to on-tick. If you say, for example, (on-tick next-color 1) then big-bang will wait 1 second between calls to next-color.
Remember to follow the HtDW recipe! Be sure to do a proper domain analysis before starting to work on the code file.
Note: If you want to design a slightly simpler version of the program, you can modify it to display a single circle that changes color, ratherthan three stacked circles.
| constant info | changing info | big-bang option |
|---|---|---|
| COLOR NUM: 3 | ||
| COLOR :red yellow green | number sub 1 after 1 gaptime | on-tick |
| STYLE: solid outline | STYLE switch after 1 GAPTIME | |
| CIRCLE SIZE: 30 | to-draw |
|
| TYPE: circle | ||
| background: black | ||
| GAPTIME: 1 |
实现一个最粗糙版:
用到了之前的next-color 的结构,以及(boxify i) 来制作单个灯泡的背景色
(require 2htdp/image)
(require 2htdp/universe)
;; Constants:
(define SIZE 30) ; light's size
(define GAPTIME 1) ; the gap time between the light's change
;; Data definitions:
(define-struct light-cell (color style))
;; Define light-cell instances
(define red-light (make-light-cell "red" "solid"))
(define yellow-light (make-light-cell "yellow" "solid"))
(define green-light (make-light-cell "green" "solid"))
;; Functions:
;; Draws a box around given image
(define (boxify i)
(overlay i (rectangle (+ (image-width i) (/ SIZE 3))
(+ (image-height i) (/ SIZE 3))
"solid"
"black")))
;; Draws a light-cell as an image
(define (draw-light light)
(boxify (circle SIZE (light-cell-style light) (light-cell-color light))))
;; Draws traffic lights based on the current color
(define (draw-lights color)
(cond
[(string=? color "red")
(beside (draw-light red-light)
(draw-light (make-light-cell "yellow" "outline"))
(draw-light (make-light-cell "green" "outline")))]
[(string=? color "yellow")
(beside (draw-light (make-light-cell "red" "outline"))
(draw-light yellow-light)
(draw-light (make-light-cell "green" "outline")))]
[(string=? color "green")
(beside (draw-light (make-light-cell "red" "outline"))
(draw-light (make-light-cell "yellow" "outline"))
(draw-light green-light))]))
;; Defines the next color in the traffic light sequence
(define (next-color color)
(cond
[(string=? color "red") "yellow"]
[(string=? color "yellow") "green"]
[(string=? color "green") "red"]))
;; Defines the stop condition, which is always false to keep the animation running
(define (stop-when-handler color)
false)
;; Starts the animation with the given initial color
(define (start-animation initial-color)
(big-bang initial-color
(on-tick next-color GAPTIME)
(to-draw draw-lights)
(stop-when stop-when-handler)))
;; Starts the animation with the initial color "red"
(start-animation "red")
然后想在这个基础上实现无限的颜色: 这样比较好看。

考虑能不能把颜色弄成一个list,并且可以取到任意一个index的内容,结论是可行,但是这个函数已经内置过了,也就是:
(list-ref lst n)早被定义过了,用不到我哈哈哈哈。chatGPT: (define CL (list "red" "yellow" "green")) ; color-lights ;; List -> String ;; get the x index data of list ;; use (list-ref CL 1) will return "yellow" (define (list-ref lst n) (if (0? n) (first lst) (list-ref (rest list) (sub1 n))))好奇list是否有find-index,毕竟 访问index对应的数据已经有
(list-ref lst n)来内置实现了。结果是没有, 但可以自己实现,通过递归。(递归真是计算机的暴力元件了)chatGPT: ; 定义一个函数,返回元素在列表中的索引 (define (index-of lst element) (index-of-helper lst element 0)) ; 辅助函数,带有当前索引 (define (index-of-helper lst element current-index) (cond [(empty? lst) -1] ; 如果列表为空,返回 -1 表示未找到 [(equal? (first lst) element) current-index] ; 找到元素,返回当前索引 [else (index-of-helper (rest lst) element (+ current-index 1))])) ; 递归调用,索引加 1 ; 测试函数 (index-of CL "red") ; 应该返回 0 (index-of CL "yellow") ; 应该返回 1 (index-of CL "green") ; 应该返回 2 (index-of CL "blue") ; 应该返回 -1,表示未找到
chatGPT: 完成了大部分..........(要我干啥
(require 2htdp/image)
(require 2htdp/universe)
;; Constants:
(define SIZE 30) ; light's size
(define GAPTIME 1) ; the gap time between the light's change
;; Define a list of colors:
(define CL (list "red" "yellow" "green" "blue" "purple" "orange" "cyan" "magenta" "lime" "pink"))
;; Functions:
;; Draws a box around given image
(define (boxify i)
(overlay i (rectangle (+ (image-width i) (/ SIZE 3))
(+ (image-height i) (/ SIZE 3))
"solid"
"black")))
;; Draws a light with the given color and style
(define (draw-light color style)
(boxify (circle SIZE style color)))
;; Helper function to draw traffic lights based on the current color
(define (draw-lights-helper colors images current-color)
(cond
[(empty? colors) images]
[(string=? (first colors) current-color)
(draw-lights-helper (rest colors)
(beside images (draw-light (first colors) "solid"))
current-color)]
[else
(draw-lights-helper (rest colors)
(beside images (draw-light (first colors) "outline"))
current-color)]))
;; Draws traffic lights based on the current color
(define (draw-lights current-color)
(draw-lights-helper CL empty-image current-color))
;; Finds the index of an element in a list
(define (index-of lst elem)
(cond
[(empty? lst) -1]
[(equal? (first lst) elem) 0]
[else (+ 1 (index-of (rest lst) elem))]))
;; Defines the next color in the traffic light sequence
(define (next-color current-color)
(list-ref CL (modulo (+ 1 (index-of CL current-color)) (length CL))))
;; Defines the stop condition, which is always false to keep the animation running
(define (stop-when-handler color)
false)
;; Starts the animation with the given initial color
(define (start-animation initial-color)
(big-bang initial-color
(on-tick next-color GAPTIME)
(to-draw draw-lights)
(stop-when stop-when-handler)))
;; Starts the animation with the initial color "red"
(start-animation "green")
3b: Compound Data
这部分开始讲复合数据类型,3a中猫的动画,已经尝试用过了struct 来定义x和y坐标两个数据,第一个感受是比较麻烦。展示的时候要用(cat-x cat) (cat-y cat) 这样的形式,想要针对值重新覆盖,则需要(make-cat mouse-x mouse-y) .
Q:用最简单的形式,讲解一下BSL语言中, data define 里 struct如何应用。
ChatGPT:
在 BSL(Beginning Student Language)中,
struct是一种用来定义复合数据类型的机制。通过define-struct,我们可以创建包含多个字段的数据结构,然后可以使用这些结构来存储和操作相关的数据。示例:定义一个表示二维点的结构
我们将定义一个表示二维平面上点的结构,包含
x和y两个坐标。步骤
- 定义结构:使用
define-struct定义结构。- 创建实例:使用结构的构造函数创建结构的实例。
- 访问字段:使用自动生成的访问函数访问结构的字段。
- 修改字段:使用自动生成的修改函数创建新的结构实例。
示例代码
;; 1. 定义结构 (define-struct point (x y)) ;; 2. 创建结构的实例 (define p1 (make-point 3 4)) (define p2 (make-point 7 1)) ;; 3. 访问字段 (point-x p1) ; 结果是 3 (point-y p1) ; 结果是 4 ;; 4. 修改字段 (define p3 (make-point (point-x p1) (+ (point-y p1) 10))) ; p3 是 (3, 14) ;; 显示结果 p1 ; 显示 (make-point 3 4) p2 ; 显示 (make-point 7 1) p3 ; 显示 (make-point 3 14)解释
- 定义结构:
define-struct用来定义一个名为point的结构,包含两个字段:x和y。- 它会自动生成以下函数:
make-point:构造函数,用于创建point的实例。point-x:访问函数,用于访问point实例的x字段。point-y:访问函数,用于访问point实例的y字段。- 创建结构的实例:
make-point是构造函数,用来创建point结构的实例。p1是一个点,x坐标是 3,y坐标是 4。p2是另一个点,x坐标是 7,y坐标是 1。- 访问字段:
point-x函数用来获取点的x坐标。point-y函数用来获取点的y坐标。- 修改字段:
- 通过构造一个新的
point实例来修改字段的值。- 在这个例子中,
p3是一个新的点,其x坐标与p1相同,但y坐标增加了 10。总结
通过
define-struct定义的结构使得我们可以方便地创建和操作复合数据类型。这种机制非常适合用于组织和管理相关的数据,从而使代码更加简洁和易于理解。
define-struct
A structure definition defines:
constructor:
make-<structure-name>selector(s) :
<structure-name>-<field-name>predicate:
<structure-name>?(define-structure pos(x y)) defines:
constructor:make-pos
selectors:pos-x pos-y
predicate: pos?
(define-struct pos (x y))
;; constructor
(define P1 (make-pos 3 5))
(define P2 (make-pos 2 6))
;;selector
(pos-x P1);3
(pos-y P2);6
;;predicate
(pos? P1) ;true
(pos? 12) ;false
(pos? (+ 4 6));false
Compound Data Definitions
PROBLEM:
Design a data definition to represent hockey players, including both their first and last names.
remember the fundamental job of a template is to tell you what do you have to work with and what's the basic structure of the function.
请记住,模板的基本工作是告诉您必须使用什幺以及函数的基本结构是什幺。
if you write a function that consumes a player as an argument, then what it has to work with is all of the fields of the player, in this case, fn and ln. So basically, the fundamental shape of the function is take the player apart into its constituent field values and do something with them.
听着,如果你编写一个使用player作为参数的函数,那幺它必须处理的是player的所有字段,在本例中为 fn 和 ln。因此,基本上,函数的基本形状是将player拆解到其组成字段值中,并对它们执行某些操作。
(define-struct player (fn ln))
;; player is (make-player String String)
;; interp. (make-player fn ln)is a hockey player with
;; first name , fn
;; last name , ln
(define P1(make-player "Bobby" "Orr"))
(define P2(make-player "Wayne" "Gretzky"))
(define (fn-for-player p)
(... (player-fn p) ;String
(player-ln p)) ;String
)
;; templete rules used:
;; - compound: 2 fields
Practice Problems - Compound Data
这part的练习来得特别快
PROBLEM A:
Design a data definition to represent a movie, including title, budget, and year released.
To help you to create some examples, find some interesting movie facts below:
"Titanic" - budget: 200000000 released: 1997
"Avatar" - budget: 237000000 released: 2009
"The Avengers" - budget: 220000000 released: 2012
However, feel free to resarch more on your own!
PROBLEM B:
You have a list of movies you want to watch, but you like to watch your rentals in chronological order. Design a function that consumes two movies and produces the title of the most recently released movie.
Note that the rule for templating a function that consumes two compound data parameters is for the template to include all the selectors for both parameters.
;; =================
;; Data definitions:
(define-struct movie (title budget year))
;; movie is (make-movie String Number Number)
;; interp. (make-movie title budget year)is a movie with
;; movie title, title
;; movie budget , budget
;; year released, year
(define M1(make-movie "Titanic" 200000000 1997))
(define M2(make-movie "Avatar" 237000000 2009))
(define M3(make-movie "The Avengers" 220000000 2012))
(define (fn-for-movie m)
(... (movie-title m) ;String
( movie-budget m) ;Number
( movie-year m) ;Number
)
)
;; templete rules used:
;; - compound: 3 fields
;; =================
;; Functions:
;; Movie Movie -> String
;; Produce the title of the most recently released movie
(check-expect (recent-movie M1 M2) "Avatar")
(define (recent-movie movie1 movie2)
(cond
[(> (movie-year movie1) (movie-year movie2)) (movie-title movie1)]
[(< (movie-year movie1) (movie-year movie2)) (movie-title movie2)]
[else (movie-title movie2)])) ;; If they have the same year, return the title of the second movie
哎,做的我兴趣缺缺,虽然格式规范很重要,但是确实很无聊。(
PROBLEM A:
Design a data definition to help a teacher organize their next field trip.
On the trip, lunch must be provided for all students. For each student, track
their name, their grade (from 1 to 12), and whether or not they have allergies.
PROBLEM B:
To plan for the field trip, if students are in grade 6 or below, the teacher
is responsible for keeping track of their allergies. If a student has allergies,
and is in a qualifying grade, their name should be added to a special list.
Design a function to produce true if a student name should be added to this list.
(require 2htdp/image)
(require 2htdp/universe)
;; Data definition for a student
(define-struct student (name grade allergies))
;; Examples of students
(define student1 (make-student "Alice" 5 true))
(define student2 (make-student "Bob" 8 false))
(define student3 (make-student "Charlie" 6 true))
;; Student -> Boolean
;; Produces true if the student is in grade 6 or below and has allergies
(define (add-to-allergy-list? student)
(and (<= (student-grade student) 6)
(student-allergies student)))
;; Tests
(add-to-allergy-list? student1) ; Expected: true (grade 5 and has allergies)
(add-to-allergy-list? student2) ; Expected: false (grade 8 and no allergies)
(add-to-allergy-list? student3) ; Expected: true (grade 6 and has allergies)
HtDW With Compound Data
这里参考上面的cat运动的部分,引入了一个奶牛,以及rotate 让牛掉头移动(越来越有scratch的感觉了呃但没有scratch好上手)
| constant | changing | big-bang option |
|---|---|---|
| width | x coordinate of cow | on-tick |
| height | speed of cow | to-draw |
| ctr-y | on-key | |
| mts | ||
| cow image |
compilers
计算机只能理解一种语言,而这种语言由一组由 1 和 0 组成的指令组成。这种计算机语言被恰当地称为机器语言。对计算机的一条指令可能如下所示:
| 00000 | 10011110 |
|---|
如果你想计算两个数字的总和,作为机器语言程序可能指令长这样:
| 00000 | 10011110 |
|---|---|
| 00001 | 11110100 |
| 00010 | 10011110 |
| 00011 | 11010100 |
| 00100 | 10111111 |
| 00101 | 00000000 |
因此,还是得搞点高级语言,毕竟代码是死的,人是活的,活人就会犯错。哪个更容易检查,书写,看懂 别人的代码 显而易见。如下所示的c++代码和上面的机器语言干的活一样:
int a, b, sum;
cin >> a;
cin >> b;
sum = a + b;
cout << sum << endl;
什么是complier?
人说人话高级语言,机器只听机器语言,各种compilers, interpreters, assemblers 干的事情就是当翻译。
| compiler | interpreter | assembler |
|---|---|---|
| 把高级语言转成机器语言,一次性全转 | 把高级语言转成机器语言,一行一行的转 | 把汇编语言转成机器语言 |
| C ,C++ | Ruby,Perl,Python,PHP | 汇编语言 |
C++被设计成一种编译型语言,也就是说c++代码一般被翻译成系统可以直接理解的机器语言,使得生成的程序非常高效。为此,需要一组工具,称为开发工具链(development toolchain),其核心是编译器(complier)及其链接器(linker)。
开发工具链
chatGPT解释开发工具链:
开发工具链(development toolchain)是一组工具和软件的集合,用于编写、编译、调试和部署软件应用程序。对于C++这样的编译型语言,开发工具链尤为重要,因为它们负责将人类可读的源代码转换为计算机可执行的机器语言。下面是开发工具链的主要组成部分:
- 文本编辑器:开发工具链的起点通常是文本编辑器,程序员用它来编写源代码。常见的文本编辑器包括Visual Studio Code、Sublime Text、Atom等。
- 编译器(Compiler):编译器是开发工具链的核心部分,负责将高级语言(如C++)编写的源代码转换为机器语言。对于C++,常见的编译器包括GNU Compiler Collection(GCC)、Clang等。编译器将源代码文件编译成目标文件(object files),这些文件包含机器代码的二进制表示。
- 链接器(Linker):链接器将编译器生成的目标文件以及任何必要的库文件连接在一起,创建一个可执行的程序。它负责解决外部符号引用、符号重定位等问题。在C++开发中,链接器起到了很重要的作用,尤其是在引入外部库、静态库和动态链接库时。常见的链接器包括GNU ld、Microsoft Link等。
- 调试器(Debugger):调试器是开发过程中的关键工具,用于诊断和修复代码中的错误(bug)。它允许开发人员逐行执行代码、查看变量的值以及跟踪程序执行过程。常见的调试器包括GDB、LLDB、Visual Studio Debugger等。
- 构建工具(Build Tools):构建工具用于自动化和管理项目的构建过程。它们可以处理依赖关系、编译源代码、链接目标文件,并执行其他必要的任务,以确保项目的正确构建。在C++开发中,常用的构建工具包括Make、CMake、Bazel等。
- 性能分析工具(Performance Profilers):性能分析工具帮助开发人员评估程序的性能并识别性能瓶颈。它们可以提供关于CPU使用情况、内存分配情况和函数调用频率等信息。常见的性能分析工具包括Valgrind、gprof、Intel VTune等。
以上是开发工具链中的一些关键组件,它们共同构成了一个完整的开发环境,使程序员能够高效地开发、调试和优化C++应用程序。
已经有点看得云里雾里了,但是没关系。工具链 = 干活全家桶 ,这样是不是非常的好归类。
window下c++
red panda dev c++是一款国人开发的IDE(Integrated Development Environment,IDE),可以理解成上面1-6的全家桶软件放到一个软件里。
但是都是全家桶套餐,肯德基和麦当劳都能吃饱,但里面侧重什么还是有些不同的。👉 不同的IDE对于C++的特性会选择程序不同的部分进行实现,编译器是比较关键的区别。
dev-c++(red panda dev c++的参考软件,但是后面没继续开发了):MinGW or TDM-GCC 作为底层编译器。
这一点在运行下方代码的时候:
- 保存文件到D:/libregd/c++/test.cpp,
test.cpp是文件的名字,test就是测试的意思,.cpp就是一种格式,类似word大多都叫XXXX.docx
#include <iostream>
using namespace std;
int main()
{
string x;
cin >> x;
cout << x;
}
- 运行(run)
tools output 得到下方的内容,()内的内容是自己添加的
- Filename: D:/libregd/c++/test.cpp (*a.)
- Compiler Set Name: MinGW GCC 11.2.0 64-bit Debug (*b.)
Processing C++ source file: (*c.)
------------------
C++ Compiler: D:/libregd/RedPanda-Cpp/MinGW64/bin/g++.exe (*d.)
Command: g++.exe "D:/libregd/c++/test.cpp" -o "D:/libregd/c++/test.exe" -g3 -pipe -Wall -Wextra (*e.运行了一条命令)
Compile Result:(*f. )
------------------
- Errors: 0 (*g. )
- Warnings: 0 (*h. )
- Output Filename: D:/libregd/c++/test.exe (*i. )
- Output Size: 166.63 KiB (*j. )
- Compilation Time: 0.374 secs (*k. )
让我们开始做一些整理:
| *编号 | 含义 |
|---|---|
| a. | 文件名字不仅有文件名字,还有文件名字所处的位置 |
| b. | 编译器也有名字 |
| c. | 开始编译了 |
| d. | 编译器的地址和程序名字 |
| e. | 运行了一条命令 |
| f. | 结果,有结果说明运行成功了 |
| g. | 说明是0错误,自动帮你检查的,基于别的程序员们写好的检查规则 |
| h. | 警告0,原理同上 |
| i. | 输出了一个文件, test.exe ,和.cpp 同名,但格式不同了 |
| j. | test.exe 的文件大小 |
| k. | 编译过程的使用时间,0.374秒 |
里面其实已经涵盖了很多内容了,只是乍一看感觉啥也没说。
文件路径为什么有的/有的\
Q:D:/libregd/c++ ? 我在windows下的文件不都是D:\libregd\c++这样吗?(说着打开一个文件管理器,查看路路径)
A:这是一个历史遗留问题,就像手机是安卓还是苹果一样,这里说明g++.exe还是以linux的标准来做事,针对windows做了一些小小的内部一键转换。
总结
越是靠近现代的编程生态软件,越使用linux的标准。
g++ 在windows下怎么用的?
Q: Command: g++.exe "D:/libregd/c++/test.cpp" -o "D:/libregd/c++/test.exe" -g3 -pipe -Wall -Wextra 这条命令怎么理解?
A:chatGPT:
这个命令是使用GNU编译器(g++)将一个名为 "test.cpp" 的源代码文件编译成一个可执行文件,并指定输出文件名为 "test.exe"。下面是对命令中各部分的解释:
- g++.exe: 这是GNU编译器的可执行文件。在Windows系统中,".exe" 扩展名表示可执行文件。
- "D:/libregd/c++/test.cpp": 这是待编译的源代码文件的路径。在这个例子中,源代码文件名为 "test.cpp",位于 "D:/libregd/c++/" 目录下。路径被双引号括起来,是因为路径中包含了空格,这样可以确保路径被正确解析。
- -o "D:/libregd/c++/test.exe": 这是指定编译器生成的可执行文件的输出路径和名称。在这个例子中,可执行文件将被命名为 "test.exe" 并保存在 "D:/libregd/c++/" 目录下。同样地,路径被双引号括起来。
- -g3: 这是一个编译选项,表示生成调试信息。"-g" 选项后面的数字表示调试信息的详细程度,这里的 "3" 表示生成最详细的调试信息,有助于在调试器中进行精确的源代码级别调试。
- -pipe: 这是一个编译选项,告诉编译器在编译过程中使用管道来加速编译。
- -Wall: 这是一个编译选项,表示开启所有警告信息。编译器将尽可能地检测代码中潜在的问题,并给出警告信息。
- -Wextra: 这是一个编译选项,表示开启额外的警告信息。它会启用一些额外的警告,帮助开发者捕捉更多潜在的问题。
这个命令会将 "test.cpp" 编译成一个带有调试信息的可执行文件,并将其命名为 "test.exe",保存在指定路径下。
Q:显而易见这是在windows下的command ,在linux下这个命令会是如何呢?
chatGPT:
在Linux下,相同的命令也可以使用,只是路径分隔符和可执行文件的扩展名会有所不同。下面是相同的命令在Linux下的写法:
g++ "D:/libregd/c++/test.cpp" -o "D:/libregd/c++/test" -g3 -pipe -Wall -Wextra在Linux下的主要区别有:
- 路径分隔符不同:Linux下使用的路径分隔符是斜杠(/),而不是Windows下的反斜杠(\)。
- 可执行文件没有扩展名:在Linux下,可执行文件通常不包含扩展名,所以输出文件名只是 "test",而不是 "test.exe"。
其余部分的命令格式和含义与在Windows下是相同的。
总结
看来自由度还是自己终端运行command的好。
计算机的存储容量都有哪些?
Q: Output Size: 166.63 KiB ,看起来KiB 是一种单位?能帮我科普相关的常识吗?用词简洁精要,有表格的话更好。
当谈论计算机存储容量时,常用的单位包括字节(Byte)、千字节(Kilobyte,KB)、兆字节(Megabyte,MB)、吉字节(Gigabyte,GB)等。而KiB则是其中的一种更精确的单位,表示“二进制千字节”(Kibibyte)。
下面是常见存储容量单位的表格:
单位 简称 等于 字节 B 1字节 千字节 KB 1,000字节 (10^3) 兆字节 MB 1,000,000字节 (10^6) 吉字节 GB 1,000,000,000字节 (10^9) TiB TB 1,000,000,000,000字节 (10^12) PiB PB 1,000,000,000,000,000字节 (10^15) EiB EB 1,000,000,000,000,000,000字节 (10^18) ZiB ZB 1,000,000,000,000,000,000,000字节 (10^21) YiB YB 1,000,000,000,000,000,000,000,000字节 (10^24) KiB(Kibibyte)与KB(Kilobyte)的区别在于,KB是指1000字节,而KiB是指1024字节。在计算机领域,通常会使用二进制单位(如KiB、MiB、GiB等)来更精确地表示存储容量,特别是在涉及到计算机内存、硬盘容量等方面。
总结
这么看Kib更符合计算机的规则了,但日常大家也就是KB啥的用一用,比较方便,符合直觉,现实生活也是10进制的嘛。
编译时间都花哪里去了
Q:Compilation Time: 0.374 secs 这个时间很短,而且我想知道过程到底干了啥?
A: chatGPT 给出的建议是需要考虑使用命令,也就是MINGW64,
你可以使用命令行工具来查看编译器的详细输出,其中可能包含编译时间的信息。具体的命令取决于你所使用的编译器。
在你的情况下,你使用的是g++编译器,你可以通过在命令行中添加
-ftime-report选项来生成编译时间的报告。这个选项会显示编译过程中各个阶段所花费的时间。例如,你可以这样使用命令进行编译:(
test1.cpp和上面test.cpp内容完全一样)g++.exe test1.cpp -o test1.exe -ftime-report编译完成后,编译器会输出详细的编译时间报告,其中包含了每个阶段的耗时信息,你可以从中找到编译过程所用的时间。
采用这个办法确实生成得到了一个新的test1.exe,而且通过在命令行里 ./test1.exe,可以运行
下面则是-ftime-report给出的内容:
| Phase | Time (wall) | Time (%) | Memory (sys) | Memory (%) |
|--------------------------------|-------------|----------|--------------|------------|
| Phase setup | 0.00 | 1% | 1582k | 4% |
| Phase parsing | 0.21 | 86% | 37M | 86% |
| Phase lang. deferred | 0.02 | 9% | 4042k | 9% |
| Phase opt and generate | 0.01 | 4% | 402k | 1% |
| Name lookup | 0.03 | 12% | 1663k | 4% |
| Overload resolution | 0.02 | 10% | 2906k | 7% |
| Preprocessing | 0.04 | 17% | 1796k | 4% |
| Parser (global) | 0.04 | 15% | 14M | 34% |
| Parser struct body | 0.04 | 16% | 6858k | 16% |
| Parser function body | 0.01 | 6% | 2362k | 5% |
| Parser inl. func. body | 0.01 | 6% | 1421k | 3% |
| Parser inl. meth. body | 0.02 | 7% | 2867k | 6% |
| Template instantiation | 0.07 | 29% | 11M | 27% |
| TOTAL | 0.24 | - | 43M | - |
总结
phase parsing 对于这段代码来说,时间花最多。
g++ 指定不同参数 会导致 exe文件大小区别?
通过同样的内容的cpp文件编译的,只不过一个在redpanda dev 里,一个在MINGW64 命令行里:
test.exe 167kb
test1.exe 130kb
我想知道这种区别如何导致的,结论是-g 具有很大的影响。
| 名称 | 使用的编译参数(前面都是 g++ test1.cpp -o testX.exe) | 大小(kb) |
|---|---|---|
| test1.exe | -ftime-report | 130 |
| test2.exe | -ftime-report -finput-charset=UTF-8 -fexec-charset=gbk -g3 -pipe -Wall -Wextra | 251 |
| test3.exe | -ftime-report -g3 -pipe -Wall -Wextra | 251 |
| test4.exe | -ftime-report -g3 -pipe -Wall | 251 |
| test5.exe | -ftime-report -g3 -pipe | 251 |
| test6.exe | -ftime-report -g3 | 251 |
| test7.exe | -ftime-report -g2 | 178 |
| test8.exe | -ftime-report -g1 | 133 |
chatGPT:
-g参数是用来生成调试信息的,它会将调试符号包含在可执行文件中,以便在调试程序时使用。因此,加入-g参数会增加可执行文件的大小。在你的第一条命令中,你没有加入
-g参数,因此编译器并没有生成调试信息,所以可执行文件的大小相对较小。而在第二条命令中,你加入了
-g3参数,它会生成更多的调试信息,因此可执行文件的大小会更大。通常,较大的调试信息对于深度调试来说很有用,但是在生产环境中,你可能会想要将这些信息删除以减小可执行文件的大小。所以,如果你不需要进行深度调试,可以省略
-g参数,以减小可执行文件的大小。
总结
高手用终端干活也不是没有道理,不过普通环境估计还是找个趁手的IDE就行了,初学者,我感觉啥都能凑活上。
在线Web IDE
也许windows 还是有些局限,可以使用在线的网站作为学习c++的入门来用:cpp.sh
这个网站提供了c++98,c++11,c++14,c++17,c++20,c++23作为可选的运行标准。
也可以尝试根据关键词在线c++ 获得一些别的更适合的在线可以运行c++代码的网站,比如发现了一篇几款优秀的支持C、C++在线编译器
什么叫standard(标准)?
就像iPhone 4 一路到iphone15一样,语言本身是动态发展的,就像2000年以前“牛逼”也不是一个夸人的词。
c++ 本身作为一门语言也是不断发展的。98,11,20,23,这些数字指代的是年份,那一年推出的新标准。
本笔记采用c++11作为学习的环境是因为参考的教程内容也是11年的。
参考引用
魔术方法
内容依旧是靠chatGPT,我的basic全学科导师,不过今天用上了gpt-4o,感觉速度更快。但对于人脑理解时间远远多过机器生成时间这件事,我想AI也没啥办法。
001 提到了一些魔法方法,本篇笔记主要继续针对魔法方法深入理解。
1. __repr__ 和 __str__
__repr__(self):返回一个字符串,通常应该是一个合法的 Python 表达式,可以用来重新创建这个对象。repr(obj)调用时会调用这个方法。__str__(self):返回一个适合人类阅读的字符串,str(obj)或print(obj)调用时会调用这个方法。
class Dog:
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self):
return f'Dog(name={self.name!r}, age={self.age!r})'
def __str__(self):
return f'{self.name} is {self.age} years old.'
dog = Dog('Buddy', 3)
print(repr(dog)) # 输出:Dog(name='Buddy', age=3)
print(dog) # 输出:Buddy is 3 years old.
我:f'Dog(name={self.name!r}, age={self.age!r})' 为什么会有!r ?我在输出的内容中没看到。
chatGPT:
!r是 Python 格式化字符串中的一种格式说明符,用于调用对象的__repr__方法。这比单纯使用{self.name}更明确地指示了要使用该对象的“官方”字符串表示,而不是友好的字符串表示。具体解释如下:
{self.name!r}:等同于repr(self.name),调用self.name的__repr__方法。{self.name}:等同于str(self.name),调用self.name的__str__方法。在实际输出中,如果
__repr__和__str__方法的输出相同,那么你可能不会注意到差别。但是通常__repr__会提供更多细节或能够重现对象的字符串。# 没有 `!r` 的对比 dog = Dog('Buddy', 3) print(repr(dog)) # 输出 Dog(name=Buddy, age=3) print(dog) # 输出 Buddy is 3 years old.# 有 `!r` 的对比 dog = Dog('Buddy', 3) print(repr(dog)) # 输出 Dog(name='Buddy', age=3) print(dog) # 输出 Buddy is 3 years old.使用
!r可以确保你在格式化字符串时调用对象的__repr__方法,这通常用于调试和记录。它提供了更多的细节和准确性,使输出更加明确和可复现。
2. __setitem__ 和 __getitem__
__setitem__(self, key, value):允许使用索引赋值,例如obj[key] = value。__getitem__(self, key):允许使用索引获取值,例如value = obj[key]
class Dog:
def __init__(self, name, age):
self.data = {}
self.data['name'] = name
self.data['age'] = age
def __setitem__(self, key, value):
self.data[key] = value
def __getitem__(self, key):
return self.data[key]
dog = Dog('Buddy', 3)
dog['breed'] = 'Golden Retriever'
print(dog['name']) # 输出:Buddy
print(dog['breed']) # 输出:Golden Retriever
print(dog['Buddy']) # 报错: KeyError: 'Buddy'
我:这一部分我看了以后也运行了,但是感觉印象不深刻,能像讨论__len__一样,向我示范应用吗?
chatGPT:
当然可以。
__setitem__和__getitem__魔术方法分别用于设置和获取对象的索引值。通过实现这些方法,你可以使自定义对象表现得像一个字典或列表。下面是一些详细的示例,帮助你更好地理解和应用这些方法。示例 1:自定义字典类
定义和使用
__setitem__和__getitem__class MyDict: def __init__(self): self.data = {} def __setitem__(self, key, value): self.data[key] = value def __getitem__(self, key): return self.data[key] def __repr__(self): return repr(self.data) # 创建一个自定义字典对象 my_dict = MyDict() # 使用索引赋值 my_dict['name'] = 'Alice' my_dict['age'] = 30 # 使用索引获取值 print(my_dict['name']) # 输出:Alice print(my_dict['age']) # 输出:30 # 打印整个字典 print(my_dict) # 输出:{'name': 'Alice', 'age': 30}在这个例子中,
MyDict类实现了__setitem__和__getitem__方法,使得它能够像内置的字典一样使用。示例 2:自定义列表类
定义和使用
__setitem__和__getitem__class MyList: def __init__(self, *args): self.data = list(args) def __setitem__(self, index, value): self.data[index] = value def __getitem__(self, index): return self.data[index] def __repr__(self): return repr(self.data) # 创建一个自定义列表对象 my_list = MyList(1, 2, 3, 4, 5) # 使用索引赋值 my_list[0] = 10 my_list[4] = 50 # 使用索引获取值 print(my_list[0]) # 输出:10 print(my_list[4]) # 输出:50 # 打印整个列表 print(my_list) # 输出:[10, 2, 3, 4, 50]在这个例子中,
MyList类实现了__setitem__和__getitem__方法,使得它能够像内置的列表一样使用。示例 3:带有默认值的自定义字典
增加额外功能,比如默认值
class DefaultDict: def __init__(self, default_factory): self.data = {} self.default_factory = default_factory def __setitem__(self, key, value): self.data[key] = value def __getitem__(self, key): if key in self.data: return self.data[key] else: value = self.default_factory() self.data[key] = value return value def __repr__(self): return repr(self.data) # 创建一个带有默认值的自定义字典对象 default_dict = DefaultDict(lambda: 'default') # 使用索引赋值 default_dict['name'] = 'Alice' # 使用索引获取值(存在的键) print(default_dict['name']) # 输出:Alice # 使用索引获取值(不存在的键) print(default_dict['age']) # 输出:default # 打印整个字典 print(default_dict) # 输出:{'name': 'Alice', 'age': 'default'}在这个例子中,
DefaultDict类在实现__getitem__时增加了一个功能:如果键不存在,它会使用默认工厂函数创建一个默认值。总结
通过实现
__setitem__和__getitem__魔术方法,你可以自定义对象的索引赋值和获取行为。无论是模拟字典、列表还是带有额外功能的数据结构,这些魔术方法都能提供很大的灵活性和可扩展性。
3. __len__ 和 __bool__
__len__(self):返回对象的长度,len(obj)调用时会调用这个方法。__bool__(self):定义对象的布尔值,bool(obj)调用时会调用这个方法。如果没有定义,Python 会调用__len__方法。
class Dog:
def __init__(self, name, age):
self.name = name
self.age = age
self.toys = []
def __len__(self):
return len(self.toys)
def __bool__(self):
return self.age > 0
dog = Dog('Buddy', 3)
print(len(dog)) # 输出:0
print(bool(dog)) # 输出:True
我:len() 我记得是标准python的方法,也就是说,通过设置__len__ 这个魔术方法,对对象可以进行更自定义的len计算内容的选取?
chatGPT:
是的,
len()是 Python 的内置函数,当你对一个对象调用len()时,实际上是在调用该对象的__len__方法。通过定义或重写__len__方法,你可以自定义len()函数对该对象的行为,使其返回你需要的长度值。自定义
__len__方法的示例下面是一些示例,展示如何使用
__len__方法自定义对象的长度计算:示例 1:自定义容器类
class MyList: def __init__(self, *args): self.data = list(args) def __len__(self): return len(self.data) my_list = MyList(1, 2, 3, 4, 5) print(len(my_list)) # 输出:5在这个例子中,
MyList类包含一个列表data,通过定义__len__方法,len(my_list)实际上返回的是len(self.data)。示例 2:计算字符串中元音字母的数量
class VowelString: def __init__(self, string): self.string = string def __len__(self): vowels = 'aeiouAEIOU' return sum(1 for char in self.string if char in vowels) vowel_string = VowelString("hello world") print(len(vowel_string)) # 输出:3 (e, o, o)在这个例子中,
VowelString类的__len__方法返回字符串中元音字母的数量。示例 3:计算嵌套列表的总元素数量
class NestedList: def __init__(self, nested_list): self.nested_list = nested_list def __len__(self): def count_elements(lst): count = 0 for element in lst: if isinstance(element, list): count += count_elements(element) else: count += 1 return count return count_elements(self.nested_list) nested_list = NestedList([1, [2, 3], [4, [5, 6]], 7]) print(len(nested_list)) # 输出:7在这个例子中,
NestedList类的__len__方法通过递归计算嵌套列表中的所有元素数量。
4. __call__
__call__(self, *args, **kwargs):使得对象可以像函数一样被调用。
class Dog:
def __init__(self, name):
self.name = name
def __call__(self, sound):
return f'{self.name} says {sound}'
dog = Dog('Buddy')
print(dog('woof')) # 输出:Buddy says woof
我:你强调“可以像函数一样被调用” ? 意味着在使用这个方法之前,可能会比较麻烦达到一样的效果? 另外,我对 “函数一样” 这样的表述有些疑惑,难道还有“不像函数一样”的调用吗?
chatGPT:
你提到的
__call__方法确实是一个非常强大的工具,它使得对象可以像函数一样被调用。在这个例子中,定义了一个__call__方法,因此你可以通过dog('woof')的方式调用dog对象。这种行为类似于调用函数dog('woof')。
__call__的作用和优势
- 使对象具有函数的行为:
- 在某些场景中,将对象设计成可调用的(像函数一样)可以使代码更简洁和直观。比如,你可能有一个对象需要执行某种操作,并且这种操作可能涉及内部状态或属性。
- 使用
__call__方法,可以直接对对象进行调用,而不是定义一个单独的方法。- 方便的语法:
- 如果没有
__call__方法,你可能需要通过其他方法来实现同样的功能,这会使语法变得更加冗长和复杂。例如:class Dog: def __init__(self, name): self.name = name def make_sound(self, sound): return f'{self.name} says {sound}' dog = Dog('Buddy') print(dog.make_sound('woof')) # 输出:Buddy says woof相比之下,使用
__call__方法的代码更加简洁
与其他方法的对比
- 不像函数一样的调用:指的是普通的方法调用,例如
obj.method(args)。这种调用方式需要明确地调用对象的方法,而不是直接对对象进行调用。
- 像函数一样的调用:意味着你可以直接对对象进行调用,就像调用函数一样。这种语法糖使得代码更加简洁和直观。
其他示例和应用场景
1. 使用
__call__进行数据处理class DataProcessor: def __init__(self, factor): self.factor = factor def __call__(self, data): return [x * self.factor for x in data] processor = DataProcessor(2) result = processor([1, 2, 3, 4]) print(result) # 输出:[2, 4, 6, 8]在这个例子中,
DataProcessor对象直接被调用来处理数据,而不是定义一个单独的方法。2. 模拟函数的行为
class Polynomial: def __init__(self, coefficients): self.coefficients = coefficients def __call__(self, x): result = 0 for power, coefficient in enumerate(self.coefficients): result += coefficient * (x ** power) return result p = Polynomial([1, 0, -2, 1]) # 代表多项式 x^3 - 2x^2 + 1 print(p(3)) # 输出:16 (3^3 - 2*3^2 + 1)在这个例子中,
Polynomial对象直接被调用来计算多项式的值。总结
通过实现
__call__方法,你可以使对象具有函数的行为,直接对对象进行调用。这使得代码更加简洁、灵活,并且在某些场景下可以大大简化代码的书写和阅读。如果没有__call__方法,实现类似的功能可能需要更多的代码和更复杂的调用方式。
5. __hash__
__hash__(self):返回对象的哈希值,使对象可用作字典的键或存储在集合中。
class Dog:
def __init__(self, name, age):
self.name = name
self.age = age
def __hash__(self):
return hash((self.name, self.age))
dog1 = Dog('Buddy', 3)
dog2 = Dog('Max', 5)
dogs_set = {dog1, dog2}
print(dog1 in dogs_set) # 输出:True
我 :我想深入理解__hash__,没记错的话,hash()也是一个python标准方法,等于也和len一样,__hash__等于自定义了?
chatGPT:
是的,
__hash__方法允许你自定义对象的哈希值,从而使对象能够用作字典的键或存储在集合中。hash()是 Python 的内置函数,它会调用对象的__hash__方法来生成一个整数,该整数表示对象的哈希值。
__hash__方法的作用当你将自定义对象用作字典的键或存储在集合中时,Python 会使用
hash()函数来计算对象的哈希值。默认情况下,Python 使用对象的内存地址作为哈希值。通过定义__hash__方法,你可以自定义对象的哈希值计算方式,使其基于对象的内容而不是内存地址。自定义
__hash__的示例示例 1:基于对象属性的哈希值
class Person: def __init__(self, name, age): self.name = name self.age = age def __eq__(self, other): if isinstance(other, Person): return self.name == other.name and self.age == other.age return False def __hash__(self): return hash((self.name, self.age)) # 创建两个相同属性的对象 person1 = Person('Alice', 30) person2 = Person('Alice', 30) # 验证哈希值是否相同 print(hash(person1)) # 输出:哈希值 print(hash(person2)) # 输出:与 person1 相同的哈希值 # 使用对象作为字典键 person_dict = {person1: 'Engineer'} print(person_dict[person2]) # 输出:Engineer在这个例子中,
Person类实现了__eq__和__hash__方法,使得具有相同属性的对象在哈希值和比较操作中被视为相等。使用
__hash__的注意事项
- 实现
__hash__时通常需要实现__eq__:
- 如果两个对象相等 (
__eq__返回True),那么它们的哈希值也必须相等。这是哈希表(如字典和集合)工作的基本要求。- 如果你只实现了
__hash__而没有实现__eq__,则可能导致不一致的行为。- 不可变性:
- 如果对象是可变的(即其属性可以在创建后更改),则不应实现
__hash__方法,或者在对象改变后,哈希值也应随之改变。这是因为对象的哈希值应在其生命周期内保持不变,以保证哈希表的正确工作。更复杂的示例
示例 2:带有复杂属性的对象
class Book: def __init__(self, title, author, year): self.title = title self.author = author self.year = year def __eq__(self, other): if isinstance(other, Book): return (self.title, self.author, self.year) == (other.title, other.author, other.year) return False def __hash__(self): return hash((self.title, self.author, self.year)) # 创建两个相同属性的对象 book1 = Book('1984', 'George Orwell', 1949) book2 = Book('1984', 'George Orwell', 1949) # 验证哈希值是否相同 print(hash(book1)) # 输出:哈希值 print(hash(book2)) # 输出:与 book1 相同的哈希值 # 使用对象作为字典键 library = {book1: 'Classic'} print(library[book2]) # 输出:Classic在这个例子中,
Book类的哈希值基于其标题、作者和出版年份。这确保了具有相同属性的书籍对象具有相同的哈希值,并且在哈希表操作中被视为相等。总结
通过实现
__hash__方法,你可以自定义对象的哈希值,使其基于对象的内容而不是内存地址。这在使用对象作为字典键或存储在集合中时非常有用。要确保哈希值的一致性,通常还需要实现__eq__方法,并确保对象的哈希值在其生命周期内保持不变。
感觉有点学不过来了,主打一个理解和打框架,这部分内容适合看不懂了就学,不然不用刻意学。
魔术方法分类及描述
generated by chatGPT
| 类别 | 魔术方法 | 描述 |
|---|---|---|
| 构造和析构方法 | __init__(self, ...) |
构造函数,在创建对象时调用 |
__del__(self) |
析构函数,在对象被删除时调用 | |
| 字符串表示 | __str__(self) |
返回用户友好的字符串表示,用于 str() 和 print() |
__repr__(self) |
返回正式的字符串表示,用于 repr() 和调试 |
|
| 容器类型相关 | __len__(self) |
返回容器的长度,用于 len() |
__getitem__(self, key) |
根据键获取值,用于索引操作 | |
__setitem__(self, key, value) |
根据键设置值,用于索引操作 | |
__delitem__(self, key) |
根据键删除值 | |
__iter__(self) |
返回一个迭代器,用于迭代 | |
__next__(self) |
返回下一个值,用于迭代 | |
| 数值运算 | __add__(self, other) |
定义加法操作 + |
__sub__(self, other) |
定义减法操作 - |
|
__mul__(self, other) |
定义乘法操作 * |
|
__truediv__(self, other) |
定义真除法操作 / |
|
__floordiv__(self, other) |
定义地板除法操作 // |
|
__mod__(self, other) |
定义取模操作 % |
|
__pow__(self, other) |
定义幂运算 ** |
|
| 比较操作 | __eq__(self, other) |
定义相等 == |
__ne__(self, other) |
定义不相等 != |
|
__lt__(self, other) |
定义小于 < |
|
__le__(self, other) |
定义小于等于 <= |
|
__gt__(self, other) |
定义大于 > |
|
__ge__(self, other) |
定义大于等于 >= |
|
| 哈希和布尔值 | __hash__(self) |
返回对象的哈希值,用于 hash() |
__bool__(self) |
返回布尔值,用于 bool() 和条件判断 |
|
| 上下文管理 | __enter__(self) |
进入上下文管理,用于 with 语句 |
__exit__(self, exc_type, exc_value, traceback) |
退出上下文管理 | |
| 调用 | __call__(self, ...) |
使对象可以像函数一样被调用 |
| 成员运算 | __contains__(self, item) |
成员运算,用于 in 和 not in 操作 |
| 自身运算 | __iadd__(self, other) |
定义自增操作 += |
__isub__(self, other) |
定义自减操作 -= |
|
__imul__(self, other) |
定义自乘操作 *= |
|
__itruediv__(self, other) |
定义自除操作 /= |
|
__ifloordiv__(self, other) |
定义自地板除操作 //= |
|
__imod__(self, other) |
定义自取模操作 %= |
|
__ipow__(self, other) |
定义自幂运算 **= |
|
| 内置类属性 | __dict__ |
保存类的属性和方法 |
__doc__ |
类的文档字符串 | |
__name__ |
类或函数的名称 | |
__file__ |
当前文件的路径 | |
__package__ |
所在包 | |
__module__ |
所在模块 | |
__class__ |
对象的类 | |
__slots__ |
用于限制类的属性 |
额外说明
- 比较操作的魔术方法:例如
__eq__,__ne__,__lt__, 等是为了让对象可以使用标准的比较运算符,如==,!=,<,<=,>,>=。 - 容器类型相关的魔术方法:如
__getitem__,__setitem__,__delitem__等,让自定义对象能够像列表、字典等容器类型一样进行索引操作。 - 自身运算的魔术方法:如
__iadd__,__isub__等,是为了支持增强赋值操作,如+=,-=,*=,/=等。 - 内置类属性:这些属性用于获取类或对象的相关信息,例如类的属性和方法、文档字符串、类名、文件路径、所在包和模块等。
这些魔术方法让你可以定制对象在各种情况下的行为,使得自定义对象更加灵活和强大。
我:我可以理解成,魔术方法非常多,且经常视情况而定,比起其他部分的学习,这部分可能更侧重了解?
chatGPT:
是的,你的理解是正确的。魔术方法种类繁多,它们的使用通常取决于具体的需求和情境。以下是一些关于魔术方法学习的关键点,可以帮助你更好地掌握和应用它们:
关键点总结
- 全面了解:
- 魔术方法覆盖了对象构造、析构、字符串表示、容器行为、算术操作、比较、布尔值、哈希值、上下文管理等方面。
- 学习魔术方法时,需要了解每个方法的功能和使用场景。
- 按需学习:
- 并不需要一开始就深入掌握所有魔术方法。根据实际编程需求,逐步学习和使用相应的魔术方法。
- 例如,处理容器类对象时,重点学习
__getitem__,__setitem__,__len__等相关方法;处理数值运算时,学习__add__,__sub__,__mul__等方法。- 实践应用:
- 多编写示例代码,通过实际操作理解魔术方法的作用。
- 尝试在不同场景下使用魔术方法,观察它们的行为和效果。
- 阅读文档和源码:
- Python 官方文档中对魔术方法有详细的说明和示例,是学习的宝贵资源。
- 阅读一些开源项目的源码,了解魔术方法在实际项目中的应用。
实际应用示例
示例1:自定义容器类
class MyList: def __init__(self, initial_data=None): self.data = initial_data if initial_data else [] def __getitem__(self, index): return self.data[index] def __setitem__(self, index, value): self.data[index] = value def __delitem__(self, index): del self.data[index] def __len__(self): return len(self.data) def __str__(self): return str(self.data) # 使用示例 my_list = MyList([1, 2, 3]) print(my_list) # 输出: [1, 2, 3] print(len(my_list)) # 输出: 3 print(my_list[1]) # 输出: 2 my_list[1] = 99 print(my_list) # 输出: [1, 99, 3] del my_list[1] print(my_list) # 输出: [1, 3]示例2:自定义比较操作
class Person: def __init__(self, name, age): self.name = name self.age = age def __eq__(self, other): return self.name == other.name and self.age == other.age def __lt__(self, other): return self.age < other.age # 使用示例 person1 = Person('Alice', 30) person2 = Person('Bob', 25) person3 = Person('Alice', 30) print(person1 == person3) # 输出: True print(person1 < person2) # 输出: False
插件作业
我:我想你能根据我的基础 给我1个blender的插件作业吗?(包含要求和描述) 最好能更多联系到上面的学习内容,再加上一点blender api的内容,这样我想我可以得到更多的进步。
chatGPT:
Blender 插件作业
作业描述:
- 插件名称:简单的 Blender 对象创建插件
- 目标:通过 Blender API 创建一个简单的插件,允许用户通过面板界面创建自定义立方体对象。
- 要求
- 创建一个 Blender 插件。
- 插件应该包含一个面板,用户可以在该面板上输入立方体的尺寸。
- 用户输入立方体的尺寸后,插件会在场景中创建相应的立方体对象。
作业步骤:
- 插件初始化: 创建一个新的 Python 脚本文件,例如
simple_cube_creator.py,并编写插件的初始化代码。- 面板界面: 创建一个 Blender 面板,允许用户输入立方体的尺寸。
- 操作函数: 编写一个函数,用于根据用户输入的尺寸创建立方体对象。
- 注册插件: 注册插件,使其在 Blender 中可用。
bl_info = {
"name": "Simple Cube Creator",
"blender": (2, 80, 0),
"category": "Object",
}
import bpy
class OBJECT_OT_create_cube(bpy.types.Operator):
bl_idname = "object.create_cube"
bl_label = "Create Cube"
bl_options = {'REGISTER', 'UNDO'}
size: bpy.props.FloatProperty(name="Size", default=1.0)
def execute(self, context):
bpy.ops.mesh.primitive_cube_add(size=self.size, enter_editmode=False, align='WORLD')
return {'FINISHED'}
class OBJECT_PT_cube_panel(bpy.types.Panel):
bl_label = "Cube Creator"
bl_idname = "OBJECT_PT_cube_panel"
bl_space_type = 'VIEW_3D'
bl_region_type = 'UI'
bl_category = 'Tool'
def draw(self, context):
layout = self.layout
layout.operator("object.create_cube")
def register():
bpy.utils.register_class(OBJECT_OT_create_cube)
bpy.utils.register_class(OBJECT_PT_cube_panel)
def unregister():
bpy.utils.unregister_class(OBJECT_OT_create_cube)
bpy.utils.unregister_class(OBJECT_PT_cube_panel)
if __name__ == "__main__":
register()
对象-类
面向对象程序设计的核心思想是数据抽象,继承和动态绑定。
通过使用数据抽象,我们可以将类的接口和实现分离;
使用继承,可以定义相似的类型并对其相似关系建模;
使用动态绑定,可以在一定程度上忽略相似类型的区别,而以统一的方式使用它们的对象。
—— c++ primer
类的公私变量
chatGPT,我的basic全学科导师。
class Dog:
num_dogs = 0 # 公有类变量
def __init__(self, name, age):
self.__name = name # 私有实例变量
self.age = age # 公有实例变量
Dog.num_dogs += 1
def bark(self):
print(f"{self.__name} says woof!")
def get_name(self):
return self.__name
@classmethod
def display_num_dogs(cls):
print(f"Total number of dogs: {cls.num_dogs}")
@staticmethod
def sleep():
print("All dogs are sleeping.")
def __str__(self):
return f"{self.__name} is {self.age} years old."
# 创建狗的实例
dog1 = Dog("Buddy", 3)
dog2 = Dog("Max", 5)
# 访问公有变量
print(dog1.age) # 输出:3
# 访问私有变量
# print(dog1.__name) # 会报错,因为私有变量无法直接访问
# 使用公有方法访问私有变量
print(dog1.get_name()) # 输出:Buddy
__init__
下面是关于
__init__方法的一些详细说明:
- 名称和特殊性:
__init__方法是一个特殊的方法,由两个下划线开头和结尾。这种命名约定表示这是一个特殊的方法,用于在对象创建时进行初始化。- 参数:
__init__方法的第一个参数通常是self,它代表当前对象本身。在方法内部,可以使用self来访问对象的属性和方法。除了self参数之外,__init__方法可以接受其他参数,用于在创建对象时传递初始化数据。- 对象初始化:
__init__方法主要用于初始化对象的状态。你可以在这个方法中设置对象的属性,为对象提供必要的初始值。通常,这些属性将在类的其他方法中使用,或者用于对象的其他操作。- 自动调用:当你创建一个新的对象时,Python 会自动调用该类的
__init__方法,而你无需手动调用。这确保了对象在创建后立即进行初始化,以便在创建后立即可用。- 初始化过程:在创建对象时,你可以向
__init__方法传递参数,这些参数将用于初始化对象的属性。通过传递不同的参数,可以为每个对象提供不同的初始状态。
__str__
__str__方法是 Python 中的一个特殊方法(也称为魔术方法),用于定义对象的字符串表示形式。当你使用print()函数或str()函数来打印对象时,解释器会自动调用该方法来获取对象的字符串表示。下面是
__str__方法的基本结构:def __str__(self): # 返回对象的字符串表示形式 # 可以包括对象的属性信息等 return "string_representation"
类的方法分类
4种def
# 调用公有方法
dog1.bark() # 输出:Buddy says woof!
# 调用类方法
Dog.display_num_dogs() # 输出:Total number of dogs: 2
# 调用静态方法
Dog.sleep() # 输出:All dogs are sleeping.
# 调用魔术方法
print(dog2) # 输出:Max is 5 years old.
- 普通方法 (
bark):这是一个普通方法,它接受self参数,表示对象本身。它用于打印狗的名字和 "woof!"。这个方法是对象特定的,每个对象都可以调用它。- 类方法 (
display_num_dogs):这是一个类方法,它使用@classmethod装饰器进行装饰,并接受cls参数,表示类本身。该方法用于访问和操作类变量num_dogs,并打印出当前创建的狗的数量。这个方法是针对整个类的,可以通过类名调用它,也可以通过对象调用。- 静态方法 (
sleep):这是一个静态方法,它使用@staticmethod装饰器进行装饰,不接受类或对象作为参数。它是与类相关联的功能性函数,与类的实例无关。这个方法可以通过类名或对象调用。- 魔术方法 (
__str__):这是一个魔术方法,它是在对象被打印为字符串时由解释器自动调用的。在这个例子中,它返回一个描述狗的字符串,包括狗的名字和年龄
__del__
class Dog:
def __init__(self, name):
self.name = name
def bark(self):
print(f"{self.name} says woof!")
def __del__(self):
print(f"{self.name} is being destroyed.")
# 创建对象
dog1 = Dog("Buddy")
dog2 = Dog("Max")
# 调用方法
dog1.bark() # 输出:Buddy says woof!
# 删除对象
del dog1
del dog2
小知识点
类变量
感觉类变量还挺独特的,有什么案例讲解吗?
类变量在整个类的实例中是公用的,定义在类中且在函数体之外。这些类变量可以通过类名或类的实例访问。
当谈到类变量时,一个经典的案例是创建一个计数器类,用于跟踪创建的对象数量。
在这个例子中,我们扩展了
Dog类,添加了一个类变量all_dogs,用于记录所有创建的狗的实例。在__init__()方法中,我们将每个创建的狗的实例添加到all_dogs列表中,并记录了创建时间。通过类方法display_all_dogs(),我们可以打印出所有狗的信息,包括它们的名称、年龄和创建时间。这个示例展示了类变量如何用于跟踪和记录对象的信息,从而实现更复杂的功能。
import datetime
class Dog:
num_dogs = 0 # 类变量,用于跟踪创建的狗的数量
all_dogs = [] # 类变量,用于记录所有创建的狗的实例
def __init__(self, name, age):
self.name = name
self.age = age
self.created_at = datetime.datetime.now() # 记录对象创建时间
Dog.num_dogs += 1
Dog.all_dogs.append(self) # 将创建的狗的实例添加到类变量 all_dogs 中
def bark(self):
print(f"{self.name} says woof!")
@classmethod
def display_num_dogs(cls):
print(f"Total number of dogs: {cls.num_dogs}")
@classmethod
def display_all_dogs(cls):
print("All dogs:")
for dog in cls.all_dogs:
print(f"- {dog.name}, {dog.age} years old, created at {dog.created_at}")
# 创建狗的实例
dog1 = Dog("Buddy", 3)
dog2 = Dog("Max", 5)
# 调用类方法显示狗的数量
Dog.display_num_dogs() # 输出:Total number of dogs: 2
# 调用类方法显示所有狗的信息
Dog.display_all_dogs()
实例变量
不建议使用类变量作为实例变量
在
Dog类中,我们已经定义了一个类变量num_dogs用于跟踪创建的狗的数量。现在,让我们看看如果尝试将类变量直接作为实例变量使用会发生什么:class Dog: num_dogs = 0 # 类变量,用于跟踪创建的狗的数量 def __init__(self, name): self.name = name self.num_dogs = 100 # 将类变量直接作为实例变量使用 Dog.num_dogs += 1 # 创建狗的实例 dog1 = Dog("Buddy") dog2 = Dog("Max") # 打印实例变量 print(dog1.num_dogs) # 输出:100 print(dog2.num_dogs) # 输出:100 # 打印类变量 print(Dog.num_dogs) # 输出:2在这个例子中,我们将
num_dogs类变量直接赋值给了实例变量self.num_dogs。然而,这并不会影响类变量Dog.num_dogs,因为类变量和实例变量是不同的。所以,虽然实例变量num_dogs被赋值为100,但是Dog.num_dogs仍然被正确地增加了。
实例新增方法
对于 Python 3.11,动态添加方法时需要考虑到函数绑定的问题。在 Python 3.11 中,你需要使用
types.MethodType来将函数绑定到实例上。import types def run(self): print(f"{self.name} is running!") class Dog: def __init__(self, name): self.name = name # 创建狗的实例 dog1 = Dog("Buddy") dog2 = Dog("Max") # 动态添加新方法 dog1.run = types.MethodType(run, dog1) # 调用新方法 dog1.run() # 输出:Buddy is running! dog2.run() # 报错:AttributeError: 'Dog' object has no attribute 'run'通过
types.MethodType(run, dog1)将run函数绑定到了dog1实例上,使其成为了dog1实例的方法。这样就可以成功调用dog1.run()来运行run函数了。
总结类的基础知识
generated by chatGPT
| 主题 | 描述 |
|---|---|
| 成员变量 | 成员变量是属于类的属性,在类中定义,可以在类的任何方法中使用。成员变量可以通过实例对象访问和修改。 |
| 私有变量 | 私有变量通过在变量名前加双下划线 __ 来声明,表示只能在类内部访问。私有变量不能直接通过类的实例对象访问。 |
| 成员方法 | 成员方法是在类中定义的函数,用于定义类的行为。成员方法的第一个参数通常是 self,代表类的实例对象。 |
| 类的设计 | 类的设计包括类的结构、属性和方法的设计。良好的类设计应该具备高内聚、低耦合的特点,便于扩展和维护。 |
| 构造方法 | 构造方法 __init__ 是在创建对象时自动调用的方法,用于初始化对象的属性。 |
| 析构方法 | 析构方法 __del__ 是在对象被删除时自动调用的方法,用于清理资源。 |
为了更好地理解这些概念,可以通过以下示例代码来演示:
class MyClass:
# 成员变量
class_var = "I am a class variable"
def __init__(self, value):
# 实例变量
self.instance_var = value
# 私有变量
self.__private_var = "I am private"
# 成员方法
def display_vars(self):
print(f"Class Variable: {MyClass.class_var}")
print(f"Instance Variable: {self.instance_var}")
print(f"Private Variable: {self.__private_var}")
# 私有方法
def __private_method(self):
print("This is a private method")
# 析构方法
def __del__(self):
print(f"Object with value {self.instance_var} is being destroyed")
# 创建对象
obj = MyClass("Hello")
obj.display_vars()
# 尝试访问私有变量(会报错)
# print(obj.__private_var)
# 正确访问私有变量的方式
print(obj._MyClass__private_var)
# 销毁对象
del obj
这个表格和示例代码展示了成员变量、私有变量、成员方法、构造方法和析构方法的使用方式,以及类设计中的一些原则。通过实际操作和运行这些代码,可以加深对这些概念的理解。
插件的step1
找到插件存放的位置
作为资深用户,blender会有多个版本,辛亏安装都比较讲究,放在了一个地方:D:\libregd\Blender Foundation\
Blender 3.1\
blender-3.3.12-windows-x64\
blender-3.5.0-windows-x64\
blender-3.6.4-windows-x64\
blender-4.1.0-alpha+main.7e8557e6c64e-windows.amd64-release\
我打算基于4.1 来玩,所以我进入了最后一个文件夹,在这个版本的插件文件夹(插件所在地)D:\libregd\Blender Foundation\blender-4.1.0-alpha+main.7e8557e6c64e-windows.amd64-release\4.1\scripts\addons
materials_library_vx/
__pycache__/ materials_utils/
add_camera_rigs/ measureit/
add_curve_extra_objects/ mesh_auto_mirror.py
add_curve_ivygen.py mesh_bsurfaces.py
add_curve_sapling/ mesh_f2.py
add_mesh_BoltFactory/ mesh_inset/
add_mesh_discombobulator/ mesh_looptools.py
add_mesh_extra_objects/ mesh_snap_utilities_line/
add_mesh_geodesic_domes/ mesh_tiny_cad/
amaranth/ mesh_tissue/
animation_add_corrective_shape_key.py mesh_tools/
animation_animall/ node_arrange.py
ant_landscape/ node_presets.py
archimesh/ node_wrangler/
blender_id/ object_boolean_tools.py
bone_selection_sets.py object_carver/
btrace/ object_collection_manager/
camera_turnaround.py object_color_rules.py
copy_global_transform.py object_edit_linked.py
curve_assign_shapekey.py object_fracture_cell/
curve_simplify.py object_print3d_utils/
curve_tools/ object_scatter/
cycles/ object_skinify.py
depsgraph_debug.py paint_palette.py
development_edit_operator.py pose_library/
development_icon_get.py power_sequencer/
development_iskeyfree.py precision_drawing_tools/
greasepencil_tools/ presets/
hydra_storm/ real_snow.py
io_anim_bvh/ render_copy_settings/
io_anim_camera.py render_freestyle_svg.py
io_anim_nuke_chan/ render_povray/
io_coat3D/ render_ui_animation_render.py
io_curve_svg/ rigify/
io_export_dxf/ space_clip_editor_refine_solution.py
io_export_paper_model.py space_view3d_3d_navigation.py
io_export_pc2.py space_view3d_align_tools.py
io_import_BrushSet.py space_view3d_brush_menus/
io_import_dxf/ space_view3d_copy_attributes.py
io_import_images_as_planes.py space_view3d_math_vis/
io_import_palette/ space_view3d_modifier_tools.py
io_mesh_atomic/ space_view3d_pie_menus/
io_mesh_stl/ space_view3d_spacebar_menu/
io_mesh_uv_layout/ space_view3d_stored_views/
io_scene_3ds/ storypencil/
io_scene_fbx/ sun_position/
io_scene_gltf2/ system_blend_info.py
io_scene_x3d/ system_demo_mode/
io_shape_mdd/ system_property_chart.py
lighting_dynamic_sky.py ui_translate/
lighting_tri_lights.py vdm_brush_baker/
magic_uv/ viewport_vr_preview/
新建自己的插件
新建了一个Test文件夹,内有1个文件:
__init__.py
编写init
bl_info = {
"name": "My Blender Plugin-1",
"author": "libregd",
"description": "A brief description of your plugin",
"blender": (4, 1, 0),
"location": "View3D > Tools",
"category": "meo",
"version": (1, 0)
}
# Your plugin's operators, panels, etc. can be defined here
def register():
# Register your operators, panels, etc. here
print("插件已注册")
def unregister():
# Unregister your operators, panels, etc. here
print("插件已卸载")
if __name__ == "__main__":
register()
这就是基本上是一个插件的最基础的框架,通过在blender的插件列表中刷新,就可以获取自己插件的最新版本。
作业
ver 1
我:帮我做一下作业,这是blender开发课程中python 的作业。可能和blender API相关。
# 作业1
# 尝试定义一个类 这个类用于描述网格物体
# 包含 物体名称 顶点数量 边数量,材质名称、网格位置
# 包含 更改材质名、更改网格位置、打印网格所有信息 等操作
#
# 并尝试使用这个类 定义不同特征的网格物体
chatGPT:
import bpy class MeshObject: def __init__(self, name, vertices, edges, material_name, location): self.name = name self.vertices = vertices self.edges = edges self.material_name = material_name self.location = location def change_material(self, new_material_name): self.material_name = new_material_name def change_location(self, new_location): self.location = new_location def print_info(self): print("Object Name:", self.name) print("Vertex Count:", len(self.vertices)) print("Edge Count:", len(self.edges)) print("Material Name:", self.material_name) print("Location:", self.location) # Example usage: mesh1 = MeshObject("Cube", [(0,0,0), (1,0,0), (1,1,0), (0,1,0)], [(0,1), (1,2), (2,3), (3,0)], "Red", (0,0,0)) mesh1.print_info() mesh1.change_material("Blue") mesh1.change_location((1,1,1)) mesh1.print_info()这些代码在vscode中正确运行了,(但bpy显然没有用上,不然也不可能能在vs中运行)
ver 2
我:看起来还不错,但我觉得扩展性有点差了,能不能更方便的更改所有的信息呢?
chatGPT:
import bpy class MeshObject: def __init__(self, name, vertices, edges, material_name, location): self.name = name self.vertices = vertices self.edges = edges self.material_name = material_name self.location = location def update_properties(self, name=None, vertices=None, edges=None, material_name=None, location=None): if name is not None: self.name = name if vertices is not None: self.vertices = vertices if edges is not None: self.edges = edges if material_name is not None: self.material_name = material_name if location is not None: self.location = location def print_info(self): print("Object Name:", self.name) print("Vertex Count:", len(self.vertices)) print("Edge Count:", len(self.edges)) print("Material Name:", self.material_name) print("Location:", self.location) # Example usage: mesh1 = MeshObject("Cube", [(0,0,0), (1,0,0), (1,1,0), (0,1,0)], [(0,1), (1,2), (2,3), (3,0)], "Red", (0,0,0)) mesh1.print_info() # Update all properties at once mesh1.update_properties(name="NewCube", vertices=[(0,0,0), (1,0,0), (1,1,1), (0,1,1)], edges=[(0,1), (1,2), (2,3), (3,0)], material_name="Blue", location=(1,1,1)) mesh1.print_info()这个也在vscode中正确运行了,更加符合作业要求。
ver 3
我:在blender中,mesh object 有很多种特性的物体对吧?比如圆柱体,正方形,球体,等等。如果我都想通过这个class meshObject 定义出来,好像这个代码弹性依旧不够?
chatGPT:
你说得对。如果你想使用
MeshObject类来定义各种不同特性的网格对象,你可能需要更灵活的方法来实现这一点。一种方法是使用子类化(继承)的方式来扩展MeshObject类,以便针对不同类型的网格对象添加特定的属性和方法。让我们来看看如何实现这一点: 在这个例子中,我们创建了两个子类CubeObject和SphereObject分别用于表示立方体和球体。每个子类通过调用父类MeshObject的__init__方法来初始化共同的属性,并针对特定类型的网格对象添加了额外的属性和方法。这样一来,你就可以根据需要轻松地定义不同类型的网格对象。import bpy class MeshObject: def __init__(self, name, vertices, edges, material_name, location): self.name = name self.vertices = vertices self.edges = edges self.material_name = material_name self.location = location def update_properties(self, name=None, vertices=None, edges=None, material_name=None, location=None): if name is not None: self.name = name if vertices is not None: self.vertices = vertices if edges is not None: self.edges = edges if material_name is not None: self.material_name = material_name if location is not None: self.location = location def print_info(self): print("-------------------------") print("Object Name:", self.name) print("Vertex Count:", len(self.vertices)) print("Edge Count:", len(self.edges)) print("Material Name:", self.material_name) print("Location:", self.location) class CubeObject(MeshObject): def __init__(self, name, size, material_name, location): bpy.ops.mesh.primitive_cube_add(size=size, location=location) obj = bpy.context.object vertices = [(v.co.x, v.co.y, v.co.z) for v in obj.data.vertices] edges = [(e.vertices[0], e.vertices[1]) for e in obj.data.edges] super().__init__(name, vertices, edges, material_name, location) class SphereObject(MeshObject): def __init__(self, name, radius, material_name, location): bpy.ops.mesh.primitive_uv_sphere_add(radius=radius, location=location) obj = bpy.context.object vertices = [(v.co.x, v.co.y, v.co.z) for v in obj.data.vertices] edges = [(e.vertices[0], e.vertices[1]) for e in obj.data.edges] super().__init__(name, vertices, edges, material_name, location) # Example usage: cube = CubeObject("Cube", size=2, material_name="Red", location=(0, 0, 0)) cube.print_info() sphere = SphereObject("Sphere", radius=1, material_name="Blue", location=(3, 0, 0)) sphere.print_info()这个是能够在blender中运行的,运行方式:
打开blender 4.1. 将窗口分割为4部分:
3D viewport(3D视图窗口,也就是默认窗口),info(整个blender的日志窗口)python console( 虽然排不上用场,但我喜欢开着)text editor(编辑器,可以理解成内置运行Python的IDE)把上面的代码贴到
text editor中,点击Run Script,info窗口会记录操作信息,3D viewport会出现1个cube 和 1个sphere。顶部菜单中
Window -> Toggle System Console可以打开一个类似CMD的悬浮窗口,这是默认隐藏的,它的作用是查看上面代码中print()打印的内容,方便调试。有很多看不太懂,已经需要学习了。
详解 ver 3
我:谢谢,你现在是一位python专家和blender API专家,我想就上面的代码中涉及具体实现的部分向你请教,希望你一步步的推理告诉我,请确保内容真实无误:
- 每一句起到的作用是什么?
- 为什么采用这个方法?
chatGPT:
对于
CubeObject类中的__init__方法:
bpy.ops.mesh.primitive_cube_add(size=size, location=location):这一句调用了 Blender Python API 中的原语函数bpy.ops.mesh.primitive_cube_add来创建一个指定尺寸和位置的立方体网格对象。参数size指定了立方体的尺寸,而location指定了立方体的位置。为什么采用这个方法?因为
bpy.ops.mesh.primitive_cube_add是 Blender 提供的一个方便创建基本几何体的函数,使用它可以快速创建出一个具有标准尺寸和位置的立方体网格对象。
obj = bpy.context.object:这一句获取了刚刚创建的立方体对象,并将其赋值给变量obj。为什么采用这个方法?因为在调用
bpy.ops.mesh.primitive_cube_add函数后,Blender 会自动选中新创建的立方体对象,所以我们可以通过bpy.context.object来获取到当前选中的对象。
vertices = [(v.co.x, v.co.y, v.co.z) for v in obj.data.vertices]:这一句遍历了立方体对象的顶点,并将每个顶点的坐标(x, y, z)添加到vertices列表中。为什么采用这个方法?因为立方体对象的顶点坐标保存在其数据块(
obj.data)的vertices属性中,我们可以通过遍历这些顶点来获取它们的坐标。
edges = [(e.vertices[0], e.vertices[1]) for e in obj.data.edges]:这一句遍历了立方体对象的边,并将每条边的顶点索引(v1, v2)添加到edges列表中。为什么采用这个方法?因为立方体对象的边由两个顶点索引组成,保存在其数据块的
edges属性中,我们可以通过遍历这些边来获取它们的顶点索引。
super().__init__(name, vertices, edges, material_name, location):这一句调用了父类MeshObject的__init__方法来初始化网格对象的属性,包括名称、顶点、边、材质名称和位置。为什么采用这个方法?因为我们希望在子类的
__init__方法中初始化父类的属性,以便继承父类的功能并保持代码的一致性。使用super().__init__调用父类的构造函数可以确保父类的初始化逻辑被正确执行。
我对上面内容进行了一些验证:
obj = bpy.context.object
print(f"The type of bpy.context.object is {type(obj)}")
vertices = [(v.co.x, v.co.y, v.co.z) for v in obj.data.vertices]
print(f"The type of vertices is {type(vertices)}")
print(f"vertices is : {vertices}")
edges = [(e.vertices[0], e.vertices[1]) for e in obj.data.edges]
print(f"The type of edges is {type(edges)}")
print(f"edges is : {edges}")
得到的结果:
The type of bpy.context.object is <class 'bpy_types.Object'>
The type of vertices is <class 'list'>
vertices is : [(-1.0, -1.0, -1.0), (-1.0, -1.0, 1.0), (-1.0, 1.0, -1.0), (-1.0, 1.0, 1.0), (1.0, -1.0, -1.0), (1.0, -1.0, 1.0), (1.0, 1.0, -1.0), (1.0, 1.0, 1.0)]
The type of edges is <class 'list'>
edges is : [(2, 0), (0, 1), (1, 3), (3, 2), (6, 2), (3, 7), (7, 6), (4, 6), (7, 5), (5, 4), (0, 4), (5, 1)]
-------------------------
Object Name: Cube
Vertex Count: 8
Edge Count: 12
Material Name: Red
Location: (0, 0, 0)
-
vertices (顶点)和edges(边) 都是 list 里面套tuple
-
edges 没有出现8,是因为0-7 指代的8个vertices,
(2,0)的意思是,第2个顶点指向第0个顶点。即:顶点(-1.0, 1.0, -1.0) 指向→顶点(-1.0, -1.0, -1.0)。这是一种基于拓扑的索引表示法,不需要直接存储顶点的坐标。这样做的好处是节省了内存空间,并且更容易处理网格对象的几何结构。chatGPT:在Blender 中,网格对象的边数据就是以这种形式存储的,通过顶点索引,可以唯一确定一条边连接的两个顶点。
-
在 Blender 中,边的顺序通常是根据网格对象的拓扑结构自动确定的。当你创建一个网格对象时,Blender 会根据顶点的连接关系自动构建边的顺序。这种自动构建的顺序通常是按照顶点的创建顺序来排列的,但也可能受到其他因素的影响,比如顶点的连接顺序或者边的法线方向等。
针对class SphereObject 我做了同样的验证:
class SphereObject(MeshObject):
def __init__(self, name, radius, material_name, location):
bpy.ops.mesh.primitive_uv_sphere_add(radius=radius, location=location)
obj = bpy.context.object
vertices = [(v.co.x, v.co.y, v.co.z) for v in obj.data.vertices]
print(f"The type of vertices is {type(vertices)}")
print(f"vertices is : {vertices}")
edges = [(e.vertices[0], e.vertices[1]) for e in obj.data.edges]
print(f"The type of edges is {type(edges)}")
print(f"edges is : {edges}")
super().__init__(name, vertices, edges, material_name, location)
得到的结果:
The type of bpy.context.object is <class 'bpy_types.Object'>
The type of vertices is <class 'list'>
vertices is : too much
The type of edges is <class 'list'>
edges is : too much
-------------------------
Object Name: Sphere
Vertex Count: 482
Edge Count: 992
Material Name: Blue
Location: (3, 0, 0)
-
在Blender中,
bpy.ops.mesh.primitive_uv_sphere_add函数创建的球体并不是以简单的顶点和边的形式表示的,而是以更复杂的方式进行表示,这就解释了为什么你在打印出的顶点和边的数量会有这么多。这个函数创建的球体实际上是由许多个三角形面构成的,而不是简单的顶点和边。每个面由三个顶点组成,而每个顶点都在球体的表面上。所以打印出的顶点数量会非常多,因为这些顶点是用于构成球体表面的。
另外,因为球体是一个连续的曲面,而不是由直线边界分割的平面,所以它看起来并不像立方体那样清晰可见.
-
在 Blender 的编辑模式中,你可能只看到了一个简单的球体,因为 Blender 在编辑模式下会以一种更简单的方式来显示网格,以便于编辑。在编辑模式下,Blender 会显示一个低多边形的近似网格,以提高性能和交互性。
然而,在内部数据中,球体实际上是由更多的顶点和面构成的。当你通过
bpy.ops.mesh.primitive_uv_sphere_add创建球体时,Blender 默认会使用相对较高的分辨率来表示球体的表面,以确保球体的外观足够圆滑。这就解释了为什么打印出的顶点和边的数量会很多。虽然在编辑模式下只显示了少量的面,但是这些面实际上是球体表面的一部分,并且是由更多的顶点和边构成的。因此,尽管在编辑模式下看起来简单,但球体的内部数据实际上是复杂的。
-
如果你想创建更简单的球体,可以使用
bpy.ops.mesh.primitive_uv_sphere_add函数的一些参数来控制球体的分辨率,以减少顶点和边的数量。这些参数包括segments(分段数)和ring(环数),可以通过调整它们来控制球体的复杂度。例如,你可以将这些参数设置得更低一些,以创建一个具有较少顶点和边的球体。bpy.ops.mesh.primitive_uv_sphere_add(radius=radius, location=location, segments=8, ring_count=8)得到的结果:
------------------------- Object Name: Sphere Vertex Count: 58 Edge Count: 120 Material Name: Blue Location: (3, 0, 0)
bpy.ops.mesh.primitive_uv_sphere_add(radius=radius, location=location, segments=8, ring_count=8) 不写后面的segments 和ring_count,默认会给到32,和16.所以一开始的数据特别大。但这一条生成的结果不像个uv_sphere了,所以默认的还是不错的。
ver4
我:这一部分好像有些难懂,我希望给出更有可读性,即便代码变得更多了,但是结构上对新手更友好的代码形式。
vertices = [(v.co.x, v.co.y, v.co.z) for v in obj.data.vertices]
edges = [(e.vertices[0], e.vertices[1]) for e in obj.data.edges]
chatGPT:
vertices = []
for v in obj.data.vertices:
vertex_coords = (v.co.x, v.co.y, v.co.z) # v.co 表示当前顶点的世界坐标。
vertices.append(vertex_coords) # 将坐标打包成一个元组,添加到vertics列表
edges = []
for e in obj.data.edges:
edge_indices = (e.vertices[0], e.vertices[1]) # 取得了当前边对象的第一个顶点的索引,第二个顶点的索引
edges.append(edge_indices)
所以版本4 只是对可读性进行一些优化,甚至给了另一个可读性变差,但更python味儿的代码:
vertices = [v.co[:] for v in obj.data.vertices]
edges = [(e.vertices[0], e.vertices[1]) for e in obj.data.edges]
ver 5
我:我的新问题是,这个代码可以进一步简化吗?甚至MeshObject部分采用更多bpy的功能来实现?
chatGPT:
当然可以进一步简化代码,特别是在创建 CubeObject 和 SphereObject 时可以利用更多 Blender 提供的功能来减少代码量。下面是进一步简化后的代码:
在这个简化后的版本中,我们在
CubeObject和SphereObject中去除了直接处理网格数据的代码,而是将get_vertices和get_edges方法添加到这两个类中,这些方法使用 Blender 提供的函数来获取相应的顶点和边。这样可以使代码更加清晰和易于维护。import bpy class MeshObject: def __init__(self, name, vertices, edges, material_name, location): self.name = name self.vertices = vertices self.edges = edges self.material_name = material_name self.location = location def update_properties(self, name=None, vertices=None, edges=None, material_name=None, location=None): if name is not None: self.name = name if vertices is not None: self.vertices = vertices if edges is not None: self.edges = edges if material_name is not None: self.material_name = material_name if location is not None: self.location = location def print_info(self): print("Object Name:", self.name) print("Vertex Count:", len(self.vertices)) print("Edge Count:", len(self.edges)) print("Material Name:", self.material_name) print("Location:", self.location) class CubeObject(MeshObject): def __init__(self, name, size, material_name, location): bpy.ops.mesh.primitive_cube_add(size=size, location=location) super().__init__(name, self.get_vertices(), self.get_edges(), material_name, location) def get_vertices(self): return [(v.co.x, v.co.y, v.co.z) for v in bpy.context.object.data.vertices] def get_edges(self): return [(e.vertices[0], e.vertices[1]) for e in bpy.context.object.data.edges] class SphereObject(MeshObject): def __init__(self, name, radius, material_name, location): bpy.ops.mesh.primitive_uv_sphere_add(radius=radius, location=location) super().__init__(name, self.get_vertices(), self.get_edges(), material_name, location) def get_vertices(self): return [(v.co.x, v.co.y, v.co.z) for v in bpy.context.object.data.vertices] def get_edges(self): return [(e.vertices[0], e.vertices[1]) for e in bpy.context.object.data.edges] # Example usage: cube = CubeObject("Cube", size=2, material_name="Red", location=(0, 0, 0)) cube.print_info() sphere = SphereObject("Sphere", radius=1, material_name="Blue", location=(3, 0, 0)) sphere.print_info()
我:看起来好像没区别?但是写法又有一些改变,这样做真的有好处吗?能否举例说明
chatGPT:
你是对的,这两种写法的结果确实是相同的。但是,在实际开发中,尤其是对于更复杂的场景和更多的功能,将获取数据的逻辑封装到类的方法中有几个好处:
- 封装性和抽象性: 通过将获取数据的逻辑封装到类的方法中,可以提高代码的封装性和抽象性。这样,其他开发者在阅读和理解代码时,可以更清晰地知道这些方法的作用和用途,而不需要深入了解具体的实现细节。
- 可维护性和可扩展性: 如果后续需要对获取数据的逻辑进行修改或者添加新的功能,只需要修改对应类的方法即可,而不需要修改每个调用该方法的地方。这样可以提高代码的可维护性和可扩展性,减少了代码修改的风险和成本。
- 代码重用性: 如果在其他地方也需要获取相同类型的数据,可以直接调用类的方法,而不需要重复编写相同的代码。这样可以提高代码的重用性,减少了代码冗余和重复劳动。
虽然在当前的例子中,这两种写法的结果相同,并且可能没有明显的区别,但是采用第二种写法可以使代码更具有扩展性和可维护性,尤其是在实际开发中面对更复杂的场景和更多的功能时。
作业总结
- 获得一些关于blender中点和边的存在逻辑的理解。
- 复习了一些python味儿的代码,找到一点熟悉感。
- 对类的使用和存在有一个初步的理解
- blender中运行python脚本的基础用法走通。
背景
买课《BL-插件开发》大半年了,没啥精力学习。有空了就安排上,既可以实践python基础,也可以多一种角度理解blender,长远来看,更好的支撑技术路径。
- 打算从涉及面向对象的部分开始看,毕竟我对对象不能说一无所知,可以说毫不了解。
- 记录过程中遇到的问题和解决问题的思路和办法,积极应对。(with chatGPT & teacher)
采用的配置
python啥的我早配置过了,就跳过,重点关联和这堂课比较密切相关的。
环境
- python 3.11
- windows 10
- blender 4.1.0.alpha
vscode( 插件↓↓↓)
-
Code Runner---便捷代码运行
-
Python Extension Pack
-
Python
-
MagicPython---语法高亮
-
TODO Highlight---TODO 注释高亮
blender 代码补全
fake-bpy-module ---Fake Blender Python API module collection for the code completion.
pip后即可,
- 需要先设置MagicPython,直接点击就行。vscode界面右下方。
- 导入bpy 模块
额外的发现
fake-bpy-module 采用了跟随blender版本的发布来更新不同的版本
- 随着版本的增加,会有一些API的改变。
- fake-bpy-module 实现的是:代码补全提示,而非引入这个package/module
不引入也是对的,bpy是一个非标准python包,而且基本是作用在blender这款软件内,作为插件/python控制台在用。
搁vs里写了还不是得贴到blender里去测